Welcome to Will's Blog!
Trace My Like!-
lwIP学习笔记-源码
lwIP的源码可以到官网的Source Code页面下载,下载v2.0.1 release版本,关于lwIP的源码设计文档,可以参考《Design and Implementation of the lwIP tcpIP stack.pdf》,另外官网的wiki的提供给开发者的文档Architectural Rx flow,也非常值得参考。
概述
lwIP的设计与常见的一些TCP/IP协议栈有些不同,如Linux的TCP/IP协议栈,在设计上严格区分应用层和底层协议栈之间的交互,底层的协议栈与操作系统融合,是操作系统的一部分,应用层需要调用操作系统提供的接口来实现与协议栈之间的交互,而且应用层也会抽象出一层供应用层调用的TCP/IP接口,而且在内存使用上应用层和底层协议栈也是分开的,因此存在数据的copy。lwIP一般用于实时系统,没有严格的应用层与操作系统层的区分,TCP/IP协议栈和应用层可以共享内存,因此不存在数据的copy,效率更高,消耗资源更少。 lwIP在实时系统中将TCP/IP协议栈的处理放入到一个单独的任务中,应用层的处理也可以放入这一个任务,也可以单独另外创建一个任务。lwIP中所有与操作系统相关的部分全部封装成了单独的函数或宏定义,开发者在移植的时候根据具体的操作系统来实现或重定义。因此,lwIP非常容易移植到各种版本的实时操作系统上。 lwIP是针对于嵌入式实时系统设计的TCP/IP协议栈,值得去研究一下它的设计理念和源码。
Buffer and Memory Management
pbufs
src/core/pbuf.c中的pbuf_alloc()和pbuf_free()
typedef enum { //传输层header,如tcp/udp,如调用udp_send() PBUF_TRANSPORT, //IP层header,如调用raw_send() PBUF_IP, //数据链路层header,如调用ethernet_output() PBUF_LINK, //额外的ethernet header PBUF_RAW_TX, //网卡驱动层,如调用netif->input() PBUF_RAW } pbuf_layer; typedef enum { //pbuf的data存储在RAM,常用于Tx,pbuf数据结构和data分配在连续的RAM内存 PBUF_RAM, //pbuf的data存储在ROM,pbuf数据结构与data分离在不同区域,pbuf->payload指向data,而且payload不会被copy PBUF_ROM, //类似于PBUF_ROM,data存储在RAM,但payload可能被复写 PBUF_REF, //payload指向RAM,从内存pool中分配,一般用于Rx,类似于PBUF_RAM,pbuf数据结构和data分配在连续的RAM内存。不能用于Tx! PBUF_POOL } pbuf_type; struct pbuf *pbuf_alloc(pbuf_layer layer, u16_t length, pbuf_type type) { ... //根据pbuf_layer的类型计算包头长度offset switch (layer) { ... } //根据pbuf_type类型具体进行内存分配 switch (type) { case PBUF_POOL: //从内存pool中分配,调用memp_malloc() p = (struct pbuf *)memp_malloc(MEMP_PBUF_POOL); ... //payload直接指向data,内存对齐,跳过pbuf数据结构和offset p->payload = LWIP_MEM_ALIGN((void *)((u8_t *)p + (SIZEOF_STRUCT_PBUF + offset))); ... //一个包可能会被分割成多个包,tot_len是整个pbuf chain长度 p->tot_len = length; //此pbuf包长 p->len = LWIP_MIN(length, PBUF_POOL_BUFSIZE_ALIGNED - LWIP_MEM_ALIGN_SIZE(offset)); ... p->ref = 1; r = p; //剩余长度 rem_len = length - p->len; //循环链接成pbuf chain链表 while (rem_len > 0) { //再分配一个pbuf q = (struct pbuf *)memp_malloc(MEMP_PBUF_POOL); ... //链表链接成pbuf chain r->next = q; q->tot_len = (u16_t)rem_len; q->len = LWIP_MIN((u16_t)rem_len, PBUF_POOL_BUFSIZE_ALIGNED); //payload指向data,已经没有header offset q->payload = (void *)((u8_t *)q + SIZEOF_STRUCT_PBUF); q->ref = 1; rem_len -= q->len; r = q; } break; case PBUF_RAM: //从堆内存中直接分配,pbuf数据结构和data在连续的RAM内存,没有形成pbuf chain p = (struct pbuf*)mem_malloc(LWIP_MEM_ALIGN_SIZE(SIZEOF_STRUCT_PBUF + offset) + LWIP_MEM_ALIGN_SIZE(length)); ... p->payload = LWIP_MEM_ALIGN((void *)((u8_t *)p + SIZEOF_STRUCT_PBUF + offset)); p->len = p->tot_len = length; p->next = NULL; p->type = type; ... break; case PBUF_ROM: case PBUF_REF: //从内存pool中分配,只分配pbuf数据结构大小的内存,payload后期再赋值,指向分离的data p = (struct pbuf *)memp_malloc(MEMP_PBUF); ... p->payload = NULL; p->len = p->tot_len = length; p->next = NULL; p->type = type; break; ... } p->ref = 1; p->flags = 0; return p; }通过pbuf_alloc()可见pbuf分四种类型:PBUF_POOL,PBUF_RAM,PBUF_REF,PBUF_ROM。
- PBUF_POOL
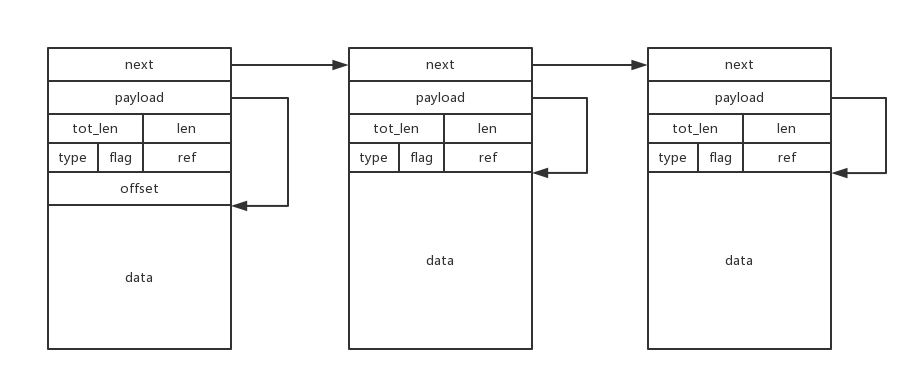
PBUF_POOL从内存pool中分配,固定长度分配,分配的每一个pbuf包都是连续内存,如果包长超过一个pbuf固定分配长度,则拆分成多个pbuf包,然后形成pbuf chain,一般用于Rx,即device drivers接收网络数据包
- PBUF_RAM
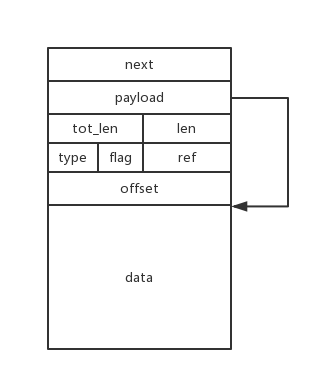
PBUF_RAM从内存堆中分配,4种类型中唯一分配方式不同的一个,非固定长度,分配在连续内存上,一般用于Tx
- PBUF_REF & PBUF_ROM
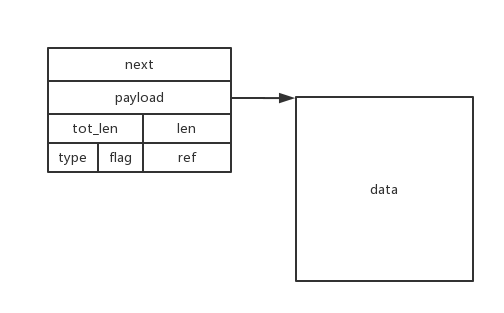
PBUF_REF和PBUF_ROM分配相同,在内存pool中分配,只分配pbuf数据结构大小,payload为NULL,将来指向data内存,pbuf数据结构和data分离,常用于应用
接着再看一下pbuf_free()
/* 官方示例:根据引用次数free()前后的变化 * 1->2->3 becomes ...1->3 * 3->3->3 becomes 2->3->3 * 1->1->2 becomes ......1 * 2->1->1 becomes 1->1->1 * 1->1->1 becomes ....... */ u8_t pbuf_free(struct pbuf *p) { ... count = 0; while (p != NULL) { ... ref = --(p->ref); if (ref == 0) { //此pbuf不再被其他pbuf引用 q = p->next; type = p->type; ... if (type == PBUF_POOL) { memp_free(MEMP_PBUF_POOL, p); } else if (type == PBUF_ROM || type == PBUF_REF) { memp_free(MEMP_PBUF, p); } else { mem_free(p); } ... count++; p = q; } else { p = NULL; //此pbuf还在被其他pbuf引用,不能free,退出 } } return count; }从pbuf_free()可以看出pbuf->ref用于记录此pbuf被引用的次数,如果不再被引用了则free掉,如果还有被引用,则减少引用记录次数,不free然后退出;如果是pbuf chain,则在遇到第一个不能free掉的pbuf后直接退出,不再继续遍历。
memeory management
通过上面的pbuf源码,可以看出lwIP有2种内存分配方式,即memp_malloc()/memp_free()和mem_malloc()/mem_free()。mem_malloc()/mem_free()与我们常用的堆分配释放类似,lwIP里面主要应对不定长的Tx时的pbuf,可以使用标准c库里的堆管理,也可以使用静态内存池,也可以使用自定义的堆管理,与前面FreeRTOS的heap_4类似的堆管理,简洁高效,尽量避免内存碎片。主要看一下memp_malloc()/memp_free(),用来应对定长的pbuf,定长的内存管理更加的简洁,效率更高,不会产生内存碎片,但是可能存在浪费空间的问题(PBUF_POOL),总要有所取舍,特别在接收时使用这种内存分配策略。
#define LWIP_MEMPOOL_DECLARE(name,num,size,desc) \ LWIP_DECLARE_MEMORY_ALIGNED(memp_memory_ ## name ## _base, ((num) * (MEMP_SIZE + MEMP_ALIGN_SIZE(size)))); \ \ LWIP_MEMPOOL_DECLARE_STATS_INSTANCE(memp_stats_ ## name) \ \ static struct memp *memp_tab_ ## name; \ \ const struct memp_desc memp_ ## name = { \ DECLARE_LWIP_MEMPOOL_DESC(desc) \ LWIP_MEMPOOL_DECLARE_STATS_REFERENCE(memp_stats_ ## name) \ LWIP_MEM_ALIGN_SIZE(size), \ (num), \ memp_memory_ ## name ## _base, \ &memp_tab_ ## name \ }; #define LWIP_MEMPOOL(name,num,size,desc) LWIP_MEMPOOL_DECLARE(name,num,size,desc) #include "lwip/priv/memp_std.h" const struct memp_desc* const memp_pools[MEMP_MAX] = { #define LWIP_MEMPOOL(name,num,size,desc) &memp_ ## name, #include "lwip/priv/memp_std.h" };上面的源码是memp相关的定义,摘录自memp.c/memp.h,另外再结合memp_std.h文件就可以明白作者的代码原理,编译阶段预处理将宏定义展开后,还原出c语言源码,而增删改查则通过头文件memp_std.h就可以完成,非常简洁的源码设计,值得学习!
... #if LWIP_UDP //通过宏LWIP_UDP控制是否定义TCP相关的静态内存pool LWIP_MEMPOOL(UDP_PCB, MEMP_NUM_UDP_PCB, sizeof(struct udp_pcb), "UDP_PCB") #endif #if LWIP_TCP //通过宏LWIP_TCP控制是否定义TCP相关的静态内存pool LWIP_MEMPOOL(TCP_PCB, MEMP_NUM_TCP_PCB, sizeof(struct tcp_pcb), "TCP_PCB") LWIP_MEMPOOL(TCP_PCB_LISTEN, MEMP_NUM_TCP_PCB_LISTEN, sizeof(struct tcp_pcb_listen), "TCP_PCB_LISTEN") LWIP_MEMPOOL(TCP_SEG, MEMP_NUM_TCP_SEG, sizeof(struct tcp_seg), "TCP_SEG") #endif ... //PBUF_REF/ROM/POOL相关的静态内存pool定义 LWIP_PBUF_MEMPOOL(PBUF, MEMP_NUM_PBUF, 0, "PBUF_REF/ROM") LWIP_PBUF_MEMPOOL(PBUF_POOL, PBUF_POOL_SIZE, PBUF_POOL_BUFSIZE, "PBUF_POOL") ... #if MEMP_USE_CUSTOM_POOLS //如果启用自定义静态内存pool来替换mem.c里面的内存管理,还需定义头文件lwippools.h #include "lwippools.h" #endif //每次#include memp_std.h,根据源码的#define,将本次的#uddef #undef LWIP_MEMPOOL #undef LWIP_MALLOC_MEMPOOL #undef LWIP_MALLOC_MEMPOOL_START #undef LWIP_MALLOC_MEMPOOL_END #undef LWIP_PBUF_MEMPOOL通过memp_std.h里的宏定义,在编译时确定静态内存pool大小,整片静态内存,分割成定长的内存块,再看pbuf.c中的memp_malloc(MEMP_PBUF_POOL)和memp_malloc(MEMP_PBUF),其中MEMP_PBUF_POOL/MEMP_PBUF是enum memp_t定义的枚举类型(源码如下所示),编译阶段展开,通过这个枚举类型在相应的连续整片的静态内存pool中分配固定长度的内存块,这些内存块形成链表的结构,定长的内存块链表在分配释放上是非常快的,而且不产生内存碎片,只是有时候有可能有些浪费内存,但是在此更倾向于效率。
#define LWIP_MEMPOOL(name,num,size,desc) #include "lwip/priv/memp_std.h" typedef enum { #define LWIP_MEMPOOL(name,num,size,desc) MEMP_##name, #include "lwip/priv/memp_std.h" MEMP_MAX } memp_t;再看几个宏定义:
#define MEMP_MEM_MALLOC 0 //采用memp_malloc/memp_free,如果此宏定义定义为1,则采用mem_malloc/mem_free #define MEM_USE_POOLS 0 //采用mem_malloc/mem_free自己的内存管理方式,如果定义为1,则采用静态内存pool这种类型的方式,此时还需要定义另一个宏和头文件 #define MEMP_USE_CUSTOM_POOLS 0 //如上所示,如果mem_malloc/mem_free采用静态内存pool的方式则需要将此宏定义为1,而且通过memp_std.h头文件可知,还需定义头文件lwippools.h,定义静态内存poolnetif
lwIP使用数据结构netif来描述一个网络接口
struct netif { struct netif *next; //指向下一个netif #if LWIP_IPV4 ip_addr_t ip_addr; //ipv4的IP地址,子网掩码,网关设置 ip_addr_t netmask; ip_addr_t gw; #endif ... netif_input_fn input; //接收函数,网卡驱动调用,送给tcp/ip stack #if LWIP_IPV4 netif_output_fn output; //发送函数,IP层要发送数据调用 #endif netif_linkoutput_fn linkoutput; //ethernet_output()发送调用,arp调用 ... void *state; //指向网卡状态,可以由网卡驱动修改,可由开发者自定义的ethernetif #ifdef netif_get_client_data void* client_data[LWIP_NETIF_CLIENT_DATA_INDEX_MAX + LWIP_NUM_NETIF_CLIENT_DATA]; #endif ... u16_t mtu; //maximum transfer unit (in bytes) u8_t hwaddr_len; //mac地址长度 u8_t hwaddr[NETIF_MAX_HWADDR_LEN]; //mac地址 u8_t flags; char name[2]; //网络接口类型描述 u8_t num; //网络接口个数 ... #if LWIP_IPV4 && LWIP_IGMP netif_igmp_mac_filter_fn igmp_mac_filter; #endif ... #if ENABLE_LOOPBACK struct pbuf *loop_first; struct pbuf *loop_last; #if LWIP_LOOPBACK_MAX_PBUFS u16_t loop_cnt_current; #endif #endif };网卡驱动初始化时用到此数据结构,参看一下测试程序的初始化就更直观了test\fuzz\fuzz.c,但是还不是具体的设备,只是一个测试程序,参考一个具体的例子
... struct netif net_test; //网络接口定义 ip4_addr_t addr; ip4_addr_t netmask; ip4_addr_t gw; u8_t pktbuf[2000]; size_t len; lwip_init(); //lwip初始化 IP4_ADDR(&addr, 172, 30, 115, 84); IP4_ADDR(&netmask, 255, 255, 255, 0); IP4_ADDR(&gw, 172, 30, 115, 1); netif_add(&net_test, &addr, &netmask, &gw, &net_test, testif_init, ethernet_input); //关注初始化函数,input函数 netif_set_up(&net_test); ...网卡的初始化的驱动文件ethernetif.c是lwIP提供的一个网卡驱动模板,err_t ethernetif_init(struct netif *netif),更底层的初始化函数static void low_level_init(struct netif *netif),以及相应的底层input/output
-
lwIP学习笔记-移植
lwIP是瑞典计算机科学院开源(BSD license)的轻量级TCP/IP协议栈,主要应用于嵌入式系统,在保持TCP/IP协议的主要功能的基础上,减少内存使用,优化处理流程,减少代码量等等。之前大部分使用的是v1.4.x版本,差不多4~5年后直接更新到了v2.x.x版本。
源码
lwIP的源码可以到官网的Source Code页面下载。下载v2.0.1 release版本,源码目录:
doc/ //文档 |-contrib.txt |-mdns.txt |-mqtt_client.txt //mqtt支持,一种流行的IoT协议 |-ppp.txt |-rwaapi.txt |-savannah.txt |-sys_arch.txt |-... src/ //源码 |-api //high-level api,如果直接使用low-level api则用不到 |-apps //应用代码,调用low-level raw api |-core //核心代码,TPC/IP stack/protocol implementations/ | //memory and buffer management/the low-level raw api |-include //头文件 |-netif //network interface device drivers |-... test/ //测试 |-fuzz //新增linux环境下fuzzing测试,使用‘american fuzzy lop’工具 |-unit //单元测试,同v1.4.x之前的版本 README ...另外,contrib的包也有用,找到对应的版本的contrib包下载。后面用到时再说明,下面是contrib包里的内容:
addons/ apps/ Coverity/ ports/移植
官方给出了Platform Developers Manual,与移植相关的部分:
Creating a platform -Porting for an OS (sys_arch.c/h, cc.h) -Porting for an OS 1.4.0 (sys_arch.c/h, cc.h) -Porting for Bare Metal environment (no OS) -Writing a device driver (netif,ethernetif...) -Available device drivers written by lwIP userslwIP可以移植到基于OS平台或者无OS的平台上,一般还是在OS的平台上使用居多,因此直接看基于OS的移植,关注v2.x.x且基于OS的移植文档。
Porting for an OS
开发者需要实现几个文件来适配OS,如cc.h/sys_arch.c/sys_arch.h;源码里面的doc/sys_arch.txt可以先阅读以下,是sys_arch相关的说明。上面提到的相应版本的contrib的包里面的ports/目录下的内容也非常值得借鉴,已经针对不同的平台实现了移植相关的文件。
ports/ |-unix //类unix系统的移植 |-win32 //windows系统的移植 |-old //不再使用,有一些嵌入式系统的例子cc.h
此文件是编译器和处理器相关的头文件描述。
- Data types定义
u8_t,u16_t,u32_t,s8_t,s16_t,s32_t及mem_ptr_t
typedef unsigned char u8_t;- printf相关的数据定义
U16_F, S16_F, X16_F, U32_F, S32_F, X32_F, SZT_F一般被定义成 “hu”, “d”, “hx”, “u”, “d”, “x”, “uz”
#define U16_F "hu"- 大端小端定义
#define BYTE_ORDER LITTLE_ENDIAN 或者 #define BYTE_ORDER BIG_ENDIANTCP/IP协议栈采用大端模式,如果处理器也支持大端模式而且使用此模式,效率是最高的;但是大部分处理器使用小端模式,这就要注意使用htons()/htonl()/ntohs()/ntohl()函数进行转换。lwIP针对这种情况提供了标准的函数,但是如果处理器或编译器有相关的优化则应该封装成平台相关的函数替换使用。如下面这样的宏定义:
#define LWIP_PLATFORM_BYTESWAP 1 #define LWIP_PLATFORM_HTONS(x) ((((u16_t)(x))>>8) | (((x)&0xFF)<<8)) #define LWIP_PLATFORM_HTONL(x) ((((u32_t)(x))>>24) | (((x)&0xFF0000)>>8) | (((x)&0xFF00)<<8) | (((x)&0xFF)<<24))- IP协议checksums选择
三种checksums算法选择:
1.load byte by byte, construct 16 bits word and add: not efficient for most platforms 2.load first byte if odd address, loop processing 16 bits words, add last byte. 3.load first byte and word if not 4 byte aligned, loop processing 32 bits words, add last word/byte.定义下面的宏选择checksums:
#define LWIP_CHKSUM_ALGORITHM 2如果是自定义checksums,则如下方式定义:
u16_t my_chksum(void *dataptr, u16_t len); #define LWIP_CHKSUM my_chksum- 内存对齐
数据结构一般通过下面这种方式定义:
#ifdef PACK_STRUCT_USE_INCLUDES # include "arch/bpstruct.h" #endif PACK_STRUCT_BEGIN struct <structure_name> { PACK_STRUCT_FIELD(<type> <field>); PACK_STRUCT_FIELD(<type> <field>); <...> } PACK_STRUCT_STRUCT; PACK_STRUCT_END #ifdef PACK_STRUCT_USE_INCLUDES # include "arch/epstruct.h" #endif根据处理器和编译器的特点,需要定义几个宏,达到内存对齐,下面是以GCC为例的定义:
#define PACK_STRUCT_FIELD(x) x __attribute__((packed)) #define PACK_STRUCT_STRUCT __attribute__((packed)) #define PACK_STRUCT_BEGIN #define PACK_STRUCT_END- 平台相关的诊断输出定义
LWIP_PLATFORM_DIAG(x) non-fatal,只是打印message LWIP_PLATFORM_ASSERT(x) fatal,打印message,然后停止执行- 抢占保护
类似FreeRTOS里面的
taskENTER_CRITICAL()和taskEXIT_CRITICAL(),lwIP源码里面使用如下面大写的宏定义,默认在src/include/lwip/sys.h里定义,lwIP推荐不要在cc.h里面定义这些宏,而是在lwipopts.h里将宏SYS_LIGHTWEIGHT_PROT=1,然后sys.h里的默认定义会生效,如下所示;然后在sys_arch.h和sys_arch.c具体实现。#define SYS_ARCH_DECL_PROTECT(lev) sys_prot_t lev #define SYS_ARCH_PROTECT(lev) lev = sys_arch_protect() #define SYS_ARCH_UNPROTECT(lev) sys_arch_unprotect(lev)sys_arch.c
此文件需要实现semaphores和mailboxes给lwIP使用。
- Semaphores
lwIP使用Counting Semaphores和Binary Semaphores。Semaphores的数据结构定义在sys_arch.h里面,源码并未给出具体的数据结构定义,完全交给开发者根据自己使用的RTOS自行决定,数据结构定义为sys_sem_t,而且需要实现下面这些函数
sys_sem_t sys_sem_new(u8_t count); void sys_sem_free(sys_sem_t sem); void sys_sem_signal(sys_sem_t sem); u32_t sys_arch_sem_wait(sys_sem_t sem, u32_t timeout);- Mailboxes
与Semaphores类似,需要根据具体的RTOS实现数据结构sys_mbox_t,像FreeRTOS是没有Mailboxes的,但是可以使用Queue代替。需要实现下面的这些函数
sys_mbox_t sys_mbox_new(int size); void sys_mbox_free(sys_mbox_t mbox); void sys_mbox_post(sys_mbox_t mbox, void *msg); u32_t sys_arch_mbox_fetch(sys_mbox_t mbox, void **msg, u32_t timeout); u32_t sys_arch_mbox_tryfetch(sys_mbox_t mbox, void **msg); err_t sys_mbox_trypost(sys_mbox_t mbox, void *msg);- Timeouts/Threads
RTOS一般都提供,也可以再做一次封装。
- System
实现lwIP的系统初始化函数
sys_init(void)sys_arch.h
需要定义下面的数据结构,结合具体使用的RTOS进行封装即可
sys_sem_t sys_mbox_t sys_thread_tSYS_MBOX_NULL, SYS_SEM_NULL直接定义成NULL。还有就是之前提到过的抢占保护,sys_arch.h中声明,sys_arch.c实现。
sys_prot_t sys_arch_protect(void); void sys_arch_unprotect(sys_prot_t pval);memory management
lwIP默认使用自己的堆管理,具体实现在mem.c/memp.c里面,需要特别注意使用。
Writing a device driver
netif/ethernetif.c文件默认是注释掉的,这是一个很好的网卡驱动模板。需要完善和修改三个函数
struct ethernetif { struct eth_addr *ethaddr; /* Add whatever per-interface state that is needed here. */ //在这里可以添加自己的私有数据结构,不是必须的 }; static void low_level_init(struct netif *netif); static err_t low_level_output(struct netif *netif, struct pbuf *p); static struct pbuf *low_level_input(struct netif *netif); static void low_level_init(struct netif *netif) { struct ethernetif *ethernetif = netif->state; /* set MAC hardware address length */ netif->hwaddr_len = ETHARP_HWADDR_LEN; //添加网卡的mac地址 /* set MAC hardware address */ netif->hwaddr[0] = ; netif->hwaddr[1] = ; netif->hwaddr[2] = ; netif->hwaddr[3] = ; netif->hwaddr[4] = ; netif->hwaddr[5] = ; /* maximum transfer unit */ netif->mtu = 1500; /* device capabilities */ /* don't set NETIF_FLAG_ETHARP if this device is not an ethernet one */ netif->flags = NETIF_FLAG_BROADCAST | NETIF_FLAG_ETHARP | NETIF_FLAG_LINK_UP; #if LWIP_IPV6 && LWIP_IPV6_MLD /* * For hardware/netifs that implement MAC filtering. * All-nodes link-local is handled by default, so we must let the hardware know * to allow multicast packets in. * Should set mld_mac_filter previously. */ if (netif->mld_mac_filter != NULL) { ip6_addr_t ip6_allnodes_ll; ip6_addr_set_allnodes_linklocal(&ip6_allnodes_ll); netif->mld_mac_filter(netif, &ip6_allnodes_ll, NETIF_ADD_MAC_FILTER); } #endif /* LWIP_IPV6 && LWIP_IPV6_MLD */ //其他相关的初始化 /* Do whatever else is needed to initialize interface. */ } static err_t low_level_output(struct netif *netif, struct pbuf *p) { struct ethernetif *ethernetif = netif->state; struct pbuf *q; //实现初始化transfer() initiate transfer(); #if ETH_PAD_SIZE pbuf_header(p, -ETH_PAD_SIZE); /* drop the padding word */ #endif for (q = p; q != NULL; q = q->next) { /* Send the data from the pbuf to the interface, one pbuf at a time. The size of the data in each pbuf is kept in the ->len variable. */ //实现发送data,从pbuf到网卡 send data from(q->payload, q->len); } //实现触发发送 signal that packet should be sent(); MIB2_STATS_NETIF_ADD(netif, ifoutoctets, p->tot_len); if (((u8_t*)p->payload)[0] & 1) { /* broadcast or multicast packet*/ MIB2_STATS_NETIF_INC(netif, ifoutnucastpkts); } else { /* unicast packet */ MIB2_STATS_NETIF_INC(netif, ifoutucastpkts); } /* increase ifoutdiscards or ifouterrors on error */ #if ETH_PAD_SIZE pbuf_header(p, ETH_PAD_SIZE); /* reclaim the padding word */ #endif LINK_STATS_INC(link.xmit); return ERR_OK; } static struct pbuf *low_level_input(struct netif *netif) { struct ethernetif *ethernetif = netif->state; struct pbuf *p, *q; u16_t len; //获得接收数据长度,赋值给len /* Obtain the size of the packet and put it into the "len" variable. */ len = ; #if ETH_PAD_SIZE len += ETH_PAD_SIZE; /* allow room for Ethernet padding */ #endif /* We allocate a pbuf chain of pbufs from the pool. */ p = pbuf_alloc(PBUF_RAW, len, PBUF_POOL); if (p != NULL) { #if ETH_PAD_SIZE pbuf_header(p, -ETH_PAD_SIZE); /* drop the padding word */ #endif /* We iterate over the pbuf chain until we have read the entire packet into the pbuf. */ for (q = p; q != NULL; q = q->next) { /* Read enough bytes to fill this pbuf in the chain. The available data in the pbuf is given by the q->len variable. This does not necessarily have to be a memcpy, you can also preallocate pbufs for a DMA-enabled MAC and after receiving truncate it to the actually received size. In this case, ensure the tot_len member of the pbuf is the sum of the chained pbuf len members. */ //实现读入数据 read data into(q->payload, q->len); } //实现数据已经读取Ack acknowledge that packet has been read(); MIB2_STATS_NETIF_ADD(netif, ifinoctets, p->tot_len); if (((u8_t*)p->payload)[0] & 1) { /* broadcast or multicast packet*/ MIB2_STATS_NETIF_INC(netif, ifinnucastpkts); } else { /* unicast packet*/ MIB2_STATS_NETIF_INC(netif, ifinucastpkts); } #if ETH_PAD_SIZE pbuf_header(p, ETH_PAD_SIZE); /* reclaim the padding word */ #endif LINK_STATS_INC(link.recv); } else { //实现丢弃数据包 drop packet(); LINK_STATS_INC(link.memerr); LINK_STATS_INC(link.drop); MIB2_STATS_NETIF_INC(netif, ifindiscards); } return p; }Porting Examples
lwIP还提供了一些移植示例。基于Cortex-M3平台的示例,示例采用lwIP源码版本v1.4.1,可以参考其cc.h和sys_arch.h的修改;而另一个示例LwIP_TCP_Echo_Server/LwIP_HTTP_Server_Netconn_RTOS里面有关于driver的参考示例。
-
RTOS学习笔记-FreeRTOS源码
通过FreeRTOS官网资料,已经可以很好的使用FreeRTOS了,再深入的理解就需要深入到源码层,接下来就阅读源码,FreeRTOS版本v9.0.0,平台为ARM Cortex-M4,编译工具为ARM MDK。
FreeRTOS需要关注的源码:
//核心代码 list.c task.c queue.c //平台相关,STM32(ARM Cortex-M4) port.c //已经分析过,Memory Management相关 heap_x.c //非核心代码 event_groups.c timers.c croutine.cList
FreeRTOS核心数据结构List,源码查看list.c,List以及ListItem数据结构如下:
/* * Definition of the only type of object that a list can contain. */ struct xLIST_ITEM { listFIRST_LIST_ITEM_INTEGRITY_CHECK_VALUE configLIST_VOLATILE TickType_t xItemValue; struct xLIST_ITEM * configLIST_VOLATILE pxNext; struct xLIST_ITEM * configLIST_VOLATILE pxPrevious; void * pvOwner; void * configLIST_VOLATILE pvContainer; listSECOND_LIST_ITEM_INTEGRITY_CHECK_VALUE }; typedef struct xLIST_ITEM ListItem_t; /* For some reason lint wants this as two separate definitions. */ /* * Definition of the type of queue used by the scheduler. */ typedef struct xLIST { listFIRST_LIST_INTEGRITY_CHECK_VALUE configLIST_VOLATILE UBaseType_t uxNumberOfItems; ListItem_t * configLIST_VOLATILE pxIndex; MiniListItem_t xListEnd; listSECOND_LIST_INTEGRITY_CHECK_VALUE } List_t;通过list.c源码的阅读,可以看出这是一个双向链表结构,图中的
List表示这个双向链表,而ListItem就是双向链表里的节点,这些节点根据xItemValue的值的大小做了排序,如下图所示: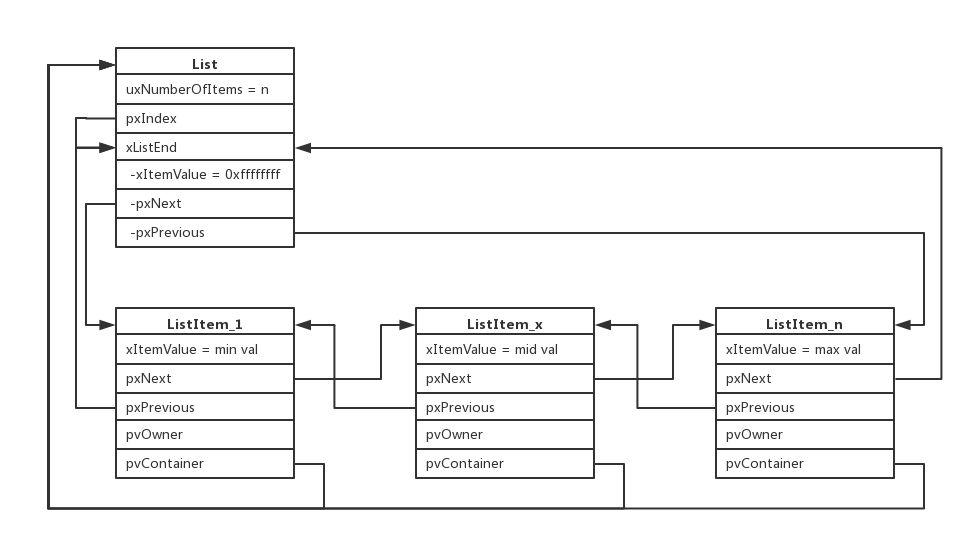
继续阅读源码,就能更深入的理解为什么这么定义数据结构,以及实际是如何使用的。
Tasks
task创建函数xTaskCreate()
BaseType_t xTaskCreate(...) { //任务控制块TCB TCB_t *pxNewTCB; ... //分配堆内存给newTask的TCB和stack,注意portSTACK_GROWTH //初始化stack pxNewTCB->pxStack = pxStack; ... //newTask初始化 prvInitialiseNewTask(...); //将task的TCB加入到Ready Tasks List prvAddNewTaskToReadyList(pxNewTCB); ... }这里有一个数据结构
TCB,这个数据结构里面定义了所有与task相关的成员,数据结构比较大,暂时先不做过多说明,继续阅读源码,在接下来的源码中剖析TCB成员,以及前面的List如何使用。static void prvInitialiseNewTask(...) { ... //如果启用Stack Overflow检查 //则将stack初始化为特定值tskSTACK_FILL_BYTE ( void ) memset( pxNewTCB->pxStack, ( int ) tskSTACK_FILL_BYTE, ( size_t ) ulStackDepth * sizeof( StackType_t ) ); ... //局部变量,先计算出stack的栈顶指针 pxTopOfStack pxTopOfStack = pxNewTCB->pxStack + ( ulStackDepth - ( uint32_t ) 1 ); //地址对齐操作,stack操作更快 pxTopOfStack = ( StackType_t * ) ( ( ( portPOINTER_SIZE_TYPE ) pxTopOfStack ) & ( ~( ( portPOINTER_SIZE_TYPE ) portBYTE_ALIGNMENT_MASK ) ) ); ... //保存pxNewTCB->pcTaskName ... //保存task优先级 pxNewTCB->uxPriority = uxPriority; #if ( configUSE_MUTEXES == 1 ) { //Mutex有优先级继承,这里保存task原始的优先级 pxNewTCB->uxBasePriority = uxPriority; pxNewTCB->uxMutexesHeld = 0; } #endif /* configUSE_MUTEXES */ //ListItem_t初始化,状态与事件ListItem //Task在Ready/Blocked/Suspended某个状态时,此ListItem_t会挂到相应的List vListInitialiseItem( &( pxNewTCB->xStateListItem ) ); //task相关的某个Event List会指向这个ListItem_t,如Queue满了而阻塞,将其挂接到等待入队的List vListInitialiseItem( &( pxNewTCB->xEventListItem ) ); //ListItem_t->pvOwener指向此task的TCB listSET_LIST_ITEM_OWNER( &( pxNewTCB->xStateListItem ), pxNewTCB ); //设置ListItem_t->xItemValue为优先级取反 //逻辑优先级是数字越大优先级越高,存储的时候取反,数字越小优先级越高 //配合前面List数据结构, 按照xItemValue大小排序,那么双链表首节点都是优先级最大的节点 listSET_LIST_ITEM_VALUE( &( pxNewTCB->xEventListItem ), ( TickType_t ) configMAX_PRIORITIES - ( TickType_t ) uxPriority ); //ListItem_t->pvOwener指向此task的TCB listSET_LIST_ITEM_OWNER( &( pxNewTCB->xEventListItem ), pxNewTCB ); ... //task notification相关初始化 #if ( configUSE_TASK_NOTIFICATIONS == 1 ) { pxNewTCB->ulNotifiedValue = 0; pxNewTCB->ucNotifyState = taskNOT_WAITING_NOTIFICATION; } #endif ... //初始化stack,详见此函数解读,可了解stack保存内容及顺序 pxNewTCB->pxTopOfStack = pxPortInitialiseStack( pxTopOfStack, pxTaskCode, pvParameters ); ... } static void prvAddNewTaskToReadyList( TCB_t *pxNewTCB ) { //进入临界区 taskENTER_CRITICAL(); { uxCurrentNumberOfTasks++; if( pxCurrentTCB == NULL ) { //没有任务或者其他任务都在Suspend状态 //全局变量pxCurrentTCB指向此task TCB,永远指向当前运行的task TCB pxCurrentTCB = pxNewTCB; if( uxCurrentNumberOfTasks == ( UBaseType_t ) 1 ) { //第一个任务,初始化Task List,详见对此函数的解读 prvInitialiseTaskLists(); } } else { //如果task调度还未开始,pxCurrentTCB指向优先级最大的那个task TCB if( xSchedulerRunning == pdFALSE ) { if( pxCurrentTCB->uxPriority <= pxNewTCB->uxPriority ) { pxCurrentTCB = pxNewTCB; } } } uxTaskNumber++; #if ( configUSE_TRACE_FACILITY == 1 ) { /* Add a counter into the TCB for tracing only. */ pxNewTCB->uxTCBNumber = uxTaskNumber; } #endif /* configUSE_TRACE_FACILITY */ //将此task TCB插入到pxReadyTasksLists相应优先级List尾部 prvAddTaskToReadyList( pxNewTCB ); ... } //退出临界区 taskEXIT_CRITICAL(); //如果此时task开始调度,如果新task优先级更高,则立即发起一次调度 if( xSchedulerRunning != pdFALSE ) { if( pxCurrentTCB->uxPriority < pxNewTCB->uxPriority ) { //强制产生一次调度,发起PendSV中断 taskYIELD_IF_USING_PREEMPTION(); } } } StackType_t *pxPortInitialiseStack(StackType_t *pxTopOfStack, TaskFunction_t pxCode, void *pvParameters) { pxTopOfStack--; //状态寄存器入栈 *pxTopOfStack = portINITIAL_XPSR; /* xPSR */ pxTopOfStack--; //PC指针入栈 *pxTopOfStack = ( ( StackType_t ) pxCode ) & portSTART_ADDRESS_MASK; /* PC */ pxTopOfStack--; //链接返回寄存器入栈,保存返回地址 *pxTopOfStack = ( StackType_t ) prvTaskExitError; /* LR */ /* Save code space by skipping register initialisation. */ pxTopOfStack -= 5; /* R12, R3, R2 and R1. */ *pxTopOfStack = ( StackType_t ) pvParameters; /* R0 */ /* A save method is being used that requires each task to maintain its own exec return value. */ pxTopOfStack--; *pxTopOfStack = portINITIAL_EXEC_RETURN; //返回值 pxTopOfStack -= 8; /* R11, R10, R9, R8, R7, R6, R5 and R4. */ return pxTopOfStack; } static void prvInitialiseTaskLists( void ) { UBaseType_t uxPriority; //每个优先级创建一个Ready List,组成Ready List数组 for( uxPriority = ( UBaseType_t ) 0U; uxPriority < ( UBaseType_t ) configMAX_PRIORITIES; uxPriority++ ) { vListInitialise( &( pxReadyTasksLists[ uxPriority ] ) ); } //创建Delay Task List vListInitialise( &xDelayedTaskList1 ); vListInitialise( &xDelayedTaskList2 ); //创建Pending Ready List vListInitialise( &xPendingReadyList ); #if ( INCLUDE_vTaskDelete == 1 ) { vListInitialise( &xTasksWaitingTermination ); } #endif /* INCLUDE_vTaskDelete */ #if ( INCLUDE_vTaskSuspend == 1 ) { //创建Suspend Task List vListInitialise( &xSuspendedTaskList ); } #endif /* INCLUDE_vTaskSuspend */ /* Start with pxDelayedTaskList using list1 and the pxOverflowDelayedTaskList using list2. */ pxDelayedTaskList = &xDelayedTaskList1; pxOverflowDelayedTaskList = &xDelayedTaskList2; }Task创建的过程已经基本清楚了,接着再看task调度过程,通过函数vTaskStartScheduler()启动调度:
void vTaskStartScheduler( void ) { //先创建Idle Task xReturn = xTaskCreate(prvIdleTask, ... ... //如果用到Timers,还要创建Timers的task #if ( configUSE_TIMERS == 1 ) { if( xReturn == pdPASS ) { xReturn = xTimerCreateTimerTask(); } } #endif /* configUSE_TIMERS */ if( xReturn == pdPASS ) { portDISABLE_INTERRUPTS(); xNextTaskUnblockTime = portMAX_DELAY; //调度开始标志置位 xSchedulerRunning = pdTRUE; //RTOS Tick初始化为0 xTickCount = ( TickType_t ) 0U; //设置systick产生RTOS需要的Tick中断,与平台移植相关,详见分析 xPortStartScheduler(); ... } ... } BaseType_t xPortStartScheduler( void ) { ... //将PendSV和SysTick中断优先级设置为最低,与RTOS运行优先级相同 portNVIC_SYSPRI2_REG |= portNVIC_PENDSV_PRI; portNVIC_SYSPRI2_REG |= portNVIC_SYSTICK_PRI; //启动Systick vPortSetupTimerInterrupt(); //初始化嵌套计数为0 uxCriticalNesting = 0; //浮点运算协处理器相关配置 prvEnableVFP(); *( portFPCCR ) |= portASPEN_AND_LSPEN_BITS; //启动第一个task prvStartFirstTask(); //不会执行到这里!!! return 0; } void vPortSetupTimerInterrupt( void ) { #if configUSE_TICKLESS_IDLE == 1 { //计算1Tick=多少Systick时钟频率计数 ulTimerCountsForOneTick = ( configSYSTICK_CLOCK_HZ / configTICK_RATE_HZ ); //低功耗每次关闭Systick的最大Tick数,更好的理解需要看前面Tickless模式低功耗的解读 xMaximumPossibleSuppressedTicks = portMAX_24_BIT_NUMBER / ulTimerCountsForOneTick; //Cpu Cycles的补偿值,还是应用在Tickless模式低功耗 ulStoppedTimerCompensation = portMISSED_COUNTS_FACTOR / ( configCPU_CLOCK_HZ / configSYSTICK_CLOCK_HZ ); } #endif /* configUSE_TICKLESS_IDLE */ //Systick tick中断加载值及使能,期望的频率是由宏configTICK_RATE_HZ定义(1ms中断) portNVIC_SYSTICK_LOAD_REG = ( configSYSTICK_CLOCK_HZ / configTICK_RATE_HZ ) - 1UL; portNVIC_SYSTICK_CTRL_REG = ( portNVIC_SYSTICK_CLK_BIT | portNVIC_SYSTICK_INT_BIT | portNVIC_SYSTICK_ENABLE_BIT ); } __asm void prvStartFirstTask( void ) { PRESERVE8 /* Use the NVIC offset register to locate the stack. */ //0xE000ED08是Cortex-M4向量表偏移量寄存器(VTOR)的地址 //起始地址存储着MSP即主堆栈指针 ldr r0, =0xE000ED08 ldr r0, [r0] ldr r0, [r0] /* Set the msp back to the start of the stack. */ msr msp, r0 /* Globally enable interrupts. */ //使能全局中断 cpsie i cpsie f dsb isb /* Call SVC to start the first task. */ svc 0 //触发SVC中断,SVC中断处理函数启动第一个task nop nop } //SVC中断处理函数 __asm void vPortSVCHandler( void ) { PRESERVE8 ldr r3, =pxCurrentTCB //将pxCurrentTCB的值作为地址赋值给r3 ldr r1, [r3] //将pxCurrentTCB指针指向的值,当前task TCB的地址赋值给r1 ldr r0, [r1] //取得当前要运行的task栈顶指针,并赋值给r0,由此理解为什么TCB数据结构的第一项必须设计为栈顶指针 ldmia r0!, {r4-r11} //寄存器r4~r11出栈 msr psp, r0 //栈顶指针赋给线程堆栈指针PSP isb mov r0, #0 msr basepri, r0 bx r14 //跳转执行目标task }三个特殊的中断及中断处理函数,Systick/SVC/PendSV,这也是在移植FreeRTOS时需要特别注意的地方,Systick产生RTOS需要的Tick中断,其中断处理函数与RTOS密切相关,SVC如上所示启动Task,PendSV用于task调度切换,Systick/PendSV配置成了最低优先级,在中断抢占的前提下,PendSV被抢占但是在处理完高优先级的任务后,依然会进入中断处理函数处理,这样不会打断高优先级的任务,也能完成任务的调度切换。
Task调度机制启动后,任务就开始执行,FreeRTOS里面的任务切换一般在PendSV中断处理函数里面进行,而PendSV中断则是由Systick中断中触发的,也就是系统Tick中断中判断是否有任务需要切换,需要则产生PendSV中断,然后再PendSV中断处理函数里面执行切换操作。另外,在xCreateTask()过程分析中(Idle Task里面也有这样的操作),我们也见到了直接切换的方式taskYIELD(),产生PendSV中断。总结2种方式:
//第一种,直接产生PendSV中断 portYIELD或者portYIELD_FROM_ISR #define portYIELD() { portNVIC_INT_CTRL_REG = portNVIC_PENDSVSET_BIT; __dsb( portSY_FULL_READ_WRITE ); __isb( portSY_FULL_READ_WRITE ); } //第二种,判断是否有task需要切换,然后再决定是否产生PendSV中断 void xPortSysTickHandler( void ) { vPortRaiseBASEPRI(); { if(xTaskIncrementTick() != pdFALSE) { portNVIC_INT_CTRL_REG = portNVIC_PENDSVSET_BIT; } } vPortClearBASEPRIFromISR(); }具体的切换过程即为PendSV的中断处理函数,汇编+C实现,还是有一些ARM Cortex-M4相关的部分放置在port.c中,而且这部分C语言也很难实现。
__asm void xPortPendSVHandler( void ) { extern uxCriticalNesting; extern pxCurrentTCB; extern vTaskSwitchContext; PRESERVE8 //先进行当前task的入栈操作,task的栈指针寄存器使用psp //中断服务程序处理之前,自动入栈xPSR、PC、LR、R12、R3~R0 mrs r0, psp isb /* Get the location of the current TCB. */ ldr r3, =pxCurrentTCB ldr r2, [r3] /* Is the task using the FPU context? If so, push high vfp registers. */ //FPU入栈 tst r14, #0x10 it eq vstmdbeq r0!, {s16-s31} /* Save the core registers. */ //其他寄存器入栈 stmdb r0!, {r4-r11, r14} /* Save the new top of stack into the first member of the TCB. */ //更新最新的栈指针到当前task TCB首地址(即第一项保存当前栈指针) str r0, [r2] //R3入栈,后面调用vTaskSwitchContext(),此函数从ReadyList里取出即将运行的task TCB赋值给pxCurrentTCB //R3保存了pxCurrentTCB地址 stmdb sp!, {r3} mov r0, #configMAX_SYSCALL_INTERRUPT_PRIORITY msr basepri, r0 dsb isb bl vTaskSwitchContext mov r0, #0 msr basepri, r0 ldmia sp!, {r3} //恢复R3,此时的pxCurrentTCB已经指向了即将运行的task TCB /* The first item in pxCurrentTCB is the task top of stack. */ //取得task TCB的栈指针 ldr r1, [r3] ldr r0, [r1] /* Pop the core registers. */ //部分寄存器出栈 ldmia r0!, {r4-r11, r14} /* Is the task using the FPU context? If so, pop the high vfp registers too. */ //FPU出栈 tst r14, #0x10 it eq vldmiaeq r0!, {s16-s31} //将task的当前栈指针赋值给psp msr psp, r0 isb bx r14 //跳转至即将运行的task运行,R0~R3、R12、LR、PC、xPSR自动出栈 }Cortex-M4提供了2个栈指针MSP和PSP,PSP就是MCU正常运行时使用的栈指针,因此一般PSP都指向了某个task的栈,而MSP在异常情况下使用,MSP一般指向的是整个系统的栈,两个栈指针寄存器分工不同。通过上面的过程,也可以看到出栈入栈的顺序:
| | Stack |-------------| | xPSR | | PC | | LR | | R12 | | R3 | | ... | | R0 | | R14 | | R11 | | ... | | R4 | <-PSP |-------------| | |Task相关的创建、调度及切换的源码基本读了一遍,还有些细节暂放一下,继续阅读。
Queue
队列应用于任务间通讯,可以在任务与任务之间,中断服务程序与任务之间传递消息,消息是通过Copy进队列的方式传递的,队列维护消息体本身,多了一次Copy而不是使用引用,对消息体本身的安全性和完整性有益。另外,Semaphore/Mutex也是借助Queue实现的,需要对Queue进一步的理解。
队列的数据结构定义为xQUEUE,此结构较大,暂时不对其细致的理解,后面阅读源码过程中深入理解,再看队列创建函数xQueueCreate(),实际是xQueueGenericCreate()函数。
QueueHandle_t xQueueGenericCreate(...) { //Queue分配堆内存 //初始化Queue prvInitialiseNewQueue(...); }为Queue分配堆内存大小及顺序:Queue_t结构体+队列消息内容占用内存总和。
|-----------------------| | Queue_t结构体 | |-----------------------| | Queue所有队列项 | |-----------------------|再看具体的Queue初始化源码:
static void prvInitialiseNewQueue(...) { ... //初始化完善Queue_t数据结构的各项 if( uxItemSize == ( UBaseType_t ) 0 ) { //Mutex时没有队列消息项,直接指向Queue_t首地址 pxNewQueue->pcHead = ( int8_t * ) pxNewQueue; } else { //队列头指向队列消息项的首地址 pxNewQueue->pcHead = ( int8_t * ) pucQueueStorage; } pxNewQueue->uxLength = uxQueueLength; pxNewQueue->uxItemSize = uxItemSize; //更多的初始化,继续深入阅读 ( void ) xQueueGenericReset(pxNewQueue, pdTRUE); ... } BaseType_t xQueueGenericReset(QueueHandle_t xQueue, BaseType_t xNewQueue) { ... taskENTER_CRITICAL(); { //tail指向队列尾 pxQueue->pcTail = pxQueue->pcHead + ( pxQueue->uxLength * pxQueue->uxItemSize ); //当前队列里的队列项个数 pxQueue->uxMessagesWaiting = ( UBaseType_t ) 0U; //指向下一个可写的队列项,用于队列入队时向队尾添加队列项 pxQueue->pcWriteTo = pxQueue->pcHead; //指向最后一个队列项,用于队列入队时向队首添加队列项 pxQueue->u.pcReadFrom = pxQueue->pcHead + ( ( pxQueue->uxLength - ( UBaseType_t ) 1U ) * pxQueue->uxItemSize ); //初始化Queue Lock时接收和发送的队列项 pxQueue->cRxLock = queueUNLOCKED; pxQueue->cTxLock = queueUNLOCKED; ... //初始化了2个List,记录了等待超时和接收消息的tasks List vListInitialise( &( pxQueue->xTasksWaitingToSend ) ); vListInitialise( &( pxQueue->xTasksWaitingToReceive ) ); } taskEXIT_CRITICAL(); return pdPASS; }初始化完成后的Queue模型如下图所示:
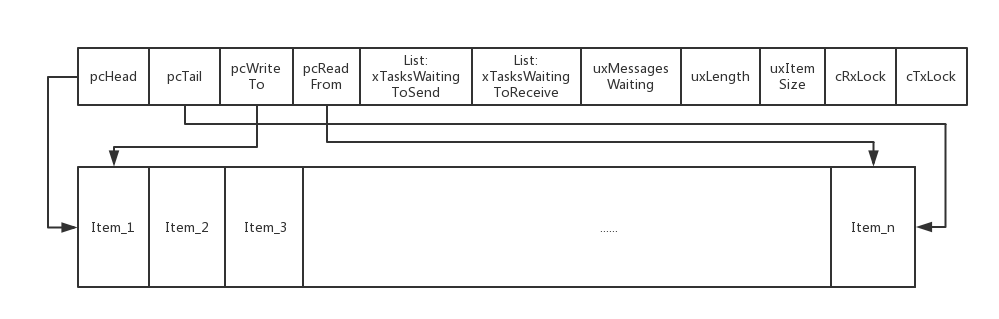
前面是Queue_t结构,后面紧跟着的Item_x为实际队列项(队列消息体),Queue_t中的两个List存储的是与此队列相关联的tasks。继续看xQueueSend()也就是xQueueGenericSend()源码
BaseType_t xQueueGenericSend(...) { ... for(;;) { taskENTER_CRITICAL(); { //检查队列是否满,如果是overwrite方式直接入队 if( ( pxQueue->uxMessagesWaiting < pxQueue->uxLength ) || ( xCopyPosition == queueOVERWRITE ) ) { //三种入队方式:队尾,队首和overwrite //特别注意当用作Mutex使用时,返回值可能为True,即需要切换到更高优先级任务,需要执行任务调度 xYieldRequired = prvCopyDataToQueue( pxQueue, pvItemToQueue, xCopyPosition ); ... //先忽略掉Queue Sets的情况 //如果有tasks正在等待接收队列消息 if( listLIST_IS_EMPTY( &( pxQueue->xTasksWaitingToReceive ) ) == pdFALSE ) { //如果有任务在等待队列消息,则将此任务添加进任务Ready List if( xTaskRemoveFromEventList( &( pxQueue->xTasksWaitingToReceive ) ) != pdFALSE ) { queueYIELD_IF_USING_PREEMPTION(); } } else if (xYieldRequired != pdFALSE) { //仅用作Mutex时,释放Mutex后调度任务(Mutex有优先级继承) queueYIELD_IF_USING_PREEMPTION(); } else { } taskEXIT_CRITICAL(); return pdPASS; } else //队列满,且非overwrite方式入队 { if( xTicksToWait == ( TickType_t ) 0 ) { //队列满了,而且没有设置超时等待,则直接退出,返回队列满错误 taskEXIT_CRITICAL(); return errQUEUE_FULL; } else if( xEntryTimeSet == pdFALSE ) { //队列满了,而且设置了超时等待,则初始化了一个timeout数据结构 vTaskSetTimeOutState( &xTimeOut ); xEntryTimeSet = pdTRUE; } else { } } } taskEXIT_CRITICAL(); //退出临界区,此处可能会有任务调度 //全部任务挂起,阻止任务调度 vTaskSuspendAll(); //锁定Queue,将Queue_t里的rxLock和txLock设置为Lock,阻止了任务调度,但是中断处理程序里还是可以对Queue进行操作,因此对Queue上锁 prvLockQueue( pxQueue ); if( xTaskCheckForTimeOut( &xTimeOut, &xTicksToWait ) == pdFALSE ) { //队列等待超时未过期 if( prvIsQueueFull( pxQueue ) != pdFALSE ) { //队列满 //将当前task加入到等待此队列入队的等待List和延时List vTaskPlaceOnEventList( &( pxQueue->xTasksWaitingToSend ), xTicksToWait ); //解锁队列 prvUnlockQueue( pxQueue ); //将tasks从PendingReadyList移至ReadyList if( xTaskResumeAll() == pdFALSE ) { portYIELD_WITHIN_API(); } } else { //队列未满 //解锁队列,恢复挂起的所有任务,没有return,继续for循环 prvUnlockQueue( pxQueue ); ( void ) xTaskResumeAll(); } } else { //设置的队列等待超时过期 prvUnlockQueue( pxQueue ); //挂起的tasks全部恢复,返回队列满错误 ( void ) xTaskResumeAll(); return errQUEUE_FULL; } } }队列入队后,如果队列未满,将等待此队列消息的List(xTasksWaitingToReceive)中需要解除阻塞的task从等待消息的List中删除,然后将其添加进任务Ready List中,然后再与当前运行的task的优先级做一下比较,如果优先级更高则产生一次调度。详见函数xTaskRemoveFromEventList()。
如果队列满了,则情况稍微复杂一些,如果队列入队时没有设置阻塞等待时间,即xTicksToWait=0,则直接返回队列满错误;如果设置了阻塞等待时间,而且时间未到,则将当前运行的task加入到等待此队列入队的等待List里(xTasksWaitingToSend),还要将此任务加入到延时List中,可参考函数vTaskPlaceOnEventList(),解锁队列,恢复所有挂起的任务,恢复调度,如果此时有更高优先级的任务Ready,则产生一次任务调度;如果设置了阻塞时间,而且时间到,则解锁Queue,恢复所有挂起的任务,恢复调度,返回队列满错误。
接着再看一下中断处理函数里相关的Queue的操作函数xQueueGenericSendFromISR()
BaseType_t xQueueGenericSendFromISR(...) { ... uxSavedInterruptStatus = portSET_INTERRUPT_MASK_FROM_ISR(); { if( ( pxQueue->uxMessagesWaiting < pxQueue->uxLength ) || ( xCopyPosition == queueOVERWRITE ) ) { //队列未满或overwrite //入队,分三种方式:队尾、队首、overwrite ( void ) prvCopyDataToQueue( pxQueue, pvItemToQueue, xCopyPosition ); if( cTxLock == queueUNLOCKED ) { //如果队列unlock ... //队列非空 if( listLIST_IS_EMPTY( &( pxQueue->xTasksWaitingToReceive ) ) == pdFALSE ) { //如果有任务在等待队列消息,则将此任务添加进任务Ready List if( xTaskRemoveFromEventList( &( pxQueue->xTasksWaitingToReceive ) ) != pdFALSE ) { //设置为pdTRUE,则代表需要一次任务切换 if( pxHigherPriorityTaskWoken != NULL ) { *pxHigherPriorityTaskWoken = pdTRUE; } } } } else { //如果队列lock,此时不可以操作队列,只有tx锁计数器加1 pxQueue->cTxLock = ( int8_t ) ( cTxLock + 1 ); } xReturn = pdPASS; } else { //队列满了,直接返回队列满错误 xReturn = errQUEUE_FULL; } } portCLEAR_INTERRUPT_MASK_FROM_ISR( uxSavedInterruptStatus ); return xReturn; }中断服务程序里的队列入队操作就要简单许多,不同的处理是在队列被锁定后,不再做任何操作了,直接将cTxLock计数器加1,在队列被解锁后,根据计数器的值,依次处理相关的队列项。
再接着看出队函数xQueueReceive(),也就是xQueueGenericReceive(),与入队的操作相反,基本逻辑非常类似。
BaseType_t xQueueGenericReceive(...) { ... for( ;; ) { taskENTER_CRITICAL(); { const UBaseType_t uxMessagesWaiting = pxQueue->uxMessagesWaiting; //等待消息队列项非空 if( uxMessagesWaiting > ( UBaseType_t ) 0 ) { pcOriginalReadPosition = pxQueue->u.pcReadFrom; //出队操作,不像前面入队那样分三种情况了,出队只有copy操作 prvCopyDataFromQueue( pxQueue, pvBuffer ); if( xJustPeeking == pdFALSE ) { //需要移除队列消息项,一般情况都采用这种操作,走这个分支 pxQueue->uxMessagesWaiting = uxMessagesWaiting - 1; #if ( configUSE_MUTEXES == 1 ) { //Mutex时的操作 if( pxQueue->uxQueueType == queueQUEUE_IS_MUTEX ) { pxQueue->pxMutexHolder = ( int8_t * ) pvTaskIncrementMutexHeldCount(); } } #endif if( listLIST_IS_EMPTY( &( pxQueue->xTasksWaitingToSend ) ) == pdFALSE ) { //队列等待发送List非空,有task在等待向队列发送消息 //将此任务添加进任务Ready List if( xTaskRemoveFromEventList( &( pxQueue->xTasksWaitingToSend ) ) != pdFALSE ) { //如果有任务需要调度,产生一次任务调度 queueYIELD_IF_USING_PREEMPTION(); } } } else { //不需要移除队列消息项 pxQueue->u.pcReadFrom = pcOriginalReadPosition; if( listLIST_IS_EMPTY( &( pxQueue->xTasksWaitingToReceive ) ) == pdFALSE ) { if( xTaskRemoveFromEventList( &( pxQueue->xTasksWaitingToReceive ) ) != pdFALSE ) { queueYIELD_IF_USING_PREEMPTION(); } } } taskEXIT_CRITICAL(); return pdPASS; } else { //等待消息队列项为空 if( xTicksToWait == ( TickType_t ) 0 ) { //设置等待阻塞超时时间为0,则直接返回队列空错误 taskEXIT_CRITICAL(); return errQUEUE_EMPTY; } else if( xEntryTimeSet == pdFALSE ) { //设置了等待阻塞超时时间,则初始化一个TimeOut数据结构 vTaskSetTimeOutState( &xTimeOut ); xEntryTimeSet = pdTRUE; } else { } } } taskEXIT_CRITICAL(); //退出临界区,此处可能会有任务调度 //所有任务挂起,阻止任务调度 vTaskSuspendAll(); //Queue锁定,此时可以处理中断,中断处理程序里可能对队列有操作 prvLockQueue( pxQueue ); if( xTaskCheckForTimeOut( &xTimeOut, &xTicksToWait ) == pdFALSE ) { //等待阻塞超时时间未到 if( prvIsQueueEmpty( pxQueue ) != pdFALSE ) { //队列未空 #if ( configUSE_MUTEXES == 1 ) { //Mutex时的操作 if( pxQueue->uxQueueType == queueQUEUE_IS_MUTEX ) { taskENTER_CRITICAL(); { vTaskPriorityInherit( ( void * ) pxQueue->pxMutexHolder ); } taskEXIT_CRITICAL(); } } #endif //将任务加入到等待接收队列消息的List和延时List vTaskPlaceOnEventList( &( pxQueue->xTasksWaitingToReceive ), xTicksToWait ); //Queue解锁 prvUnlockQueue( pxQueue ); //挂起的任务全部恢复,并启动调度 if( xTaskResumeAll() == pdFALSE ) { //如果有调度需要,产生一次调度 portYIELD_WITHIN_API(); } } esle { //队列为非空 prvUnlockQueue( pxQueue ); ( void ) xTaskResumeAll(); } } else { //等待阻塞超时时间到 //Queue解锁,恢复挂起的任务,开启任务调度 prvUnlockQueue( pxQueue ); ( void ) xTaskResumeAll(); if( prvIsQueueEmpty( pxQueue ) != pdFALSE ) { //队列未空,返回队列空错误 return errQUEUE_EMPTY; } } } }另一个中断处理程序里的函数xQueueReceiveFromISR()也与相应的入队时类似。
BaseType_t xQueueReceiveFromISR(...) { uxSavedInterruptStatus = portSET_INTERRUPT_MASK_FROM_ISR(); { const UBaseType_t uxMessagesWaiting = pxQueue->uxMessagesWaiting; if( uxMessagesWaiting > ( UBaseType_t ) 0 ) { ... //将队列消息项copy出队列 prvCopyDataFromQueue( pxQueue, pvBuffer ); pxQueue->uxMessagesWaiting = uxMessagesWaiting - 1; if( cRxLock == queueUNLOCKED ) { //队列unlock if( listLIST_IS_EMPTY( &( pxQueue->xTasksWaitingToSend ) ) == pdFALSE ) { //有task等待向队列发送消息,将此task从等待发送队列的List中移除,并加入到任务的Ready List里 if( xTaskRemoveFromEventList( &( pxQueue->xTasksWaitingToSend ) ) != pdFALSE ) { if( pxHigherPriorityTaskWoken != NULL ) { //有任务调度,将任务调度标志置位pdTRUE *pxHigherPriorityTaskWoken = pdTRUE; } } } } else { //队列lock,队列不进行操作,将rxLock计数器加1,后面队列解锁后再依次做相应的处理 pxQueue->cRxLock = ( int8_t ) ( cRxLock + 1 ); } } else { //队列里没有接收的消息,直接返回失败错误 xReturn = pdFAIL; } } portCLEAR_INTERRUPT_MASK_FROM_ISR( uxSavedInterruptStatus ); return xReturn; }Semaphore & Mutex
信号量和互斥量也是基于Queue实现的,有了前面阅读Queue相关源码的基础,继续阅读这两者就能更好的理解。
Binary Semaphore创建函数xSemaphoreCreateBinary(),从下面的宏定义看出创建了一个type为queueQUEUE_TYPE_BINARY_SEMAPHORE,队列size为1,队列项size为0的队列。
#define xSemaphoreCreateBinary() xQueueGenericCreate( ( UBaseType_t ) 1, semSEMAPHORE_QUEUE_ITEM_LENGTH, queueQUEUE_TYPE_BINARY_SEMAPHORE )Counting Semaphore创建函数xSemaphoreCreateCounting(),由下面的代码可以看出是创建一个type为queueQUEUE_TYPE_COUNTING_SEMAPHORE,队列size为创建时的参数uxMaxCount(计数最大值),队列项size为0的队列。另一个初始化时的参数uxInitialCount是信号量的初始值(即为队列里消息项的个数)。
#define xSemaphoreCreateCounting( uxMaxCount, uxInitialCount ) xQueueCreateCountingSemaphore( ( uxMaxCount ), ( uxInitialCount ) ) QueueHandle_t xQueueCreateCountingSemaphore(...) { QueueHandle_t xHandle; xHandle = xQueueGenericCreate( uxMaxCount, queueSEMAPHORE_QUEUE_ITEM_LENGTH, queueQUEUE_TYPE_COUNTING_SEMAPHORE ); if( xHandle != NULL ) { ( ( Queue_t * ) xHandle )->uxMessagesWaiting = uxInitialCount; } return xHandle; }Mutex的创建函数xSemaphoreCreateMutex(),由下面的代码可以看出,创建了一个type为queueQUEUE_TYPE_MUTEX,队列size为1,队列项size为0的队列。
#define xSemaphoreCreateMutex() xQueueCreateMutex( queueQUEUE_TYPE_MUTEX ) QueueHandle_t xQueueCreateMutex( const uint8_t ucQueueType ) { Queue_t *pxNewQueue; const UBaseType_t uxMutexLength = ( UBaseType_t ) 1, uxMutexSize = ( UBaseType_t ) 0; pxNewQueue = ( Queue_t * ) xQueueGenericCreate( uxMutexLength, uxMutexSize, ucQueueType ); prvInitialiseMutex( pxNewQueue ); return pxNewQueue; } static void prvInitialiseMutex( Queue_t *pxNewQueue ) { if( pxNewQueue != NULL ) { //实际是在Mutex情况下,将Queue_t的pcTail和pcHead赋予了新的意义 pxNewQueue->pxMutexHolder = NULL; pxNewQueue->uxQueueType = queueQUEUE_IS_MUTEX; //用于Recursive Mutex pxNewQueue->u.uxRecursiveCallCount = 0; //这里相当于先释放了Mutex,即使用Mutex第一次就可以获取资源,区别于Binary Semaphore ( void ) xQueueGenericSend( pxNewQueue, NULL, ( TickType_t ) 0U, queueSEND_TO_BACK ); } }通过Mutex和Binary Semaphore的初始化源码可以看出,在使用上Mutex创建完成后,可以直接获得资源,然后用完了再释放;而Binary Semaphore不同,创建完成后不能直接获取到,需要先释放再获取。
Recursive Mutex的创建函数xSemaphoreCreateRecursiveMutex(),实际与Mutex初始化相同,只是一个类型的区别queueQUEUE_TYPE_RECURSIVE_MUTEX,默认FreeRTOS不打开此功能。
#define xSemaphoreCreateRecursiveMutex() xQueueCreateMutex( queueQUEUE_TYPE_RECURSIVE_MUTEX )接着看Semaphore和Mutex的Take和Give,其中Binary Semaphore/Semaphore/Mutex的API相同,Recursive Mutex有单独的API
//Take操作就是Queue的出队操作 #define xSemaphoreTake( xSemaphore, xBlockTime ) xQueueGenericReceive( ( QueueHandle_t ) ( xSemaphore ), NULL, ( xBlockTime ), pdFALSE ) //特别注意Mutex不能在中断中使用,因此这个API只适用于Semaphore #define xSemaphoreTakeFromISR( xSemaphore, pxHigherPriorityTaskWoken ) xQueueReceiveFromISR( ( QueueHandle_t ) ( xSemaphore ), NULL, ( pxHigherPriorityTaskWoken ) ) //Give操作就是Queue的入队操作 #define xSemaphoreGive(xSemaphore) xQueueGenericSend( ( QueueHandle_t ) ( xSemaphore ), NULL, semGIVE_BLOCK_TIME, queueSEND_TO_BACK ) //特别注意Mutex不能在中断中使用,因此这个API只适用于Semaphore #define xSemaphoreGiveFromISR( xSemaphore, pxHigherPriorityTaskWoken ) xQueueGiveFromISR( ( QueueHandle_t ) ( xSemaphore ), ( pxHigherPriorityTaskWoken ) )Give操作就是Queue的入队操作,队列满了就返回满错误;未满则入队,计算加1,判断是否有任务阻塞,如果有则任务调度。Take操作就是Queue的出队操作,队列不为空,则计数减1,判断是否有任务入队阻塞,如果有则任务调度;队列为空,阻塞等待时间为0,则直接返回空错误;队列为空,阻塞等待时间不为0,则任务阻塞,并将任务加入延时列表。特别注意Mutex不能在中断处理函数中操作。
Recursive Mutex的Take和Give的API区别于其他3个
#define xSemaphoreTakeRecursive( xMutex, xBlockTime ) xQueueTakeMutexRecursive( ( xMutex ), ( xBlockTime ) ) BaseType_t xQueueTakeMutexRecursive( QueueHandle_t xMutex, TickType_t xTicksToWait ) { BaseType_t xReturn; Queue_t * const pxMutex = ( Queue_t * ) xMutex; if( pxMutex->pxMutexHolder == ( void * ) xTaskGetCurrentTaskHandle() ) { //非第一次调用此API,此时pxMutexHolder与当前task的TCB相同,直接uxRecursiveCallCount加1,不用去操作队列函数;如果此时是另一个任务Take,则会到下面的分支阻塞在xQueueGenericReceive //同一个任务只要递归Mutex没有将所有Take的次数Give掉,就直接进入这个分支;同一个任务一旦Give掉所有的Take次数,pxMutexHolder置为NULL,就会进入下面的分支,此时有其他任务想Take此Mutex会获得Take的机会 ( pxMutex->u.uxRecursiveCallCount )++; xReturn = pdPASS; } else { //如果第一次调用此API去Take递归Mutex,将当前Task的TCB赋值给pxMutexHolder,然后将uxRecursiveCallCount加1 //如果递归Mutex的Give所有Take的次数,将pxMutexHolder置为NULL,则又进入到这个分支,如果此时有其他任务Take递归Mutex,则会获得机会,否则只能被阻塞在xQueueGenericReceive xReturn = xQueueGenericReceive( pxMutex, NULL, xTicksToWait, pdFALSE ); if( xReturn != pdFAIL ) { ( pxMutex->u.uxRecursiveCallCount )++; } } return xReturn; } #define xSemaphoreGiveRecursive( xMutex ) xQueueGiveMutexRecursive( ( xMutex ) ) BaseType_t xQueueGiveMutexRecursive( QueueHandle_t xMutex ) { BaseType_t xReturn; Queue_t * const pxMutex = ( Queue_t * ) xMutex; //判断是否在同一个任务中Give if( pxMutex->pxMutexHolder == ( void * ) xTaskGetCurrentTaskHandle() ) { //通过uxRecursiveCallCount计数递归,每次Give操作此值减1 ( pxMutex->u.uxRecursiveCallCount )--; if( pxMutex->u.uxRecursiveCallCount == ( UBaseType_t ) 0 ) { //如果Give的次数刚好与Take的次数相等,向pxMutex队列里发送一条消息,pxMutexHolder置为NULL,这样Give次数过多就不会再走进这个分支,而是直接返回错误;另外如果有其他任务需要Take递归Mutex,则获得机会,即释放了递归Mutex ( void ) xQueueGenericSend( pxMutex, NULL, queueMUTEX_GIVE_BLOCK_TIME, queueSEND_TO_BACK ); } xReturn = pdPASS; } else { //如果不在同一个任务中直接返回错误,还有Give的次数超过了Take的次数也会走到这里 xReturn = pdFAIL; } return xReturn; }由上面的源码可以看出,Mutex需要在同一个任务中获取释放,作为资源共享锁的使用方式,pxMutexHolder会记录创建Mutex时的task TCB,Take和Give时都会判断是否是在同一个task中,如果不是直接返回错误。而Binary Semaphore没有优先级继承,而且可以在任意的任务中获取释放。
Mutex具有优先级继承,主要用作资源共享时,提升当前获得Mutex的任务的优先级至等待此资源的所有任务中的最高优先级,尽最大可能的避免优先级翻转造成的危害(高优先级任务一直得不到资源一直被挂起,或者直接死锁了)。
可以看出,Semaphore和Mutex都是使用Queue实现的,只用到了Queue的头部分,即Queue_t结构体,而Queue的队列项则为空。Binary Semaphore/Semaphore/Mutex/Recursive Mutex各有自己的创建API,最终都是调用的Queue的创建函数;Binary Semaphore/Semaphore/Mutex的Take和Give操作API相同,Recursive Mutex有自己的单独的API操作;Semaphore有中断相关的API,但是Mutex不能在中断处理程序中执行,Mutex具有优先级继承,而且必须在同一个任务中Take和Give,而Semaphore没有优先级继承,可以在任意的任务中Take,然后在任意的任务中Give,或者反过来操作。
Task Notifications
Task Notifications是FreeRTOS V8.2.0之后新增的功能,官方文档结论是比Queue/Semaphore/Mutex/Event Groups更快,使用RAM更少,可以携带长度为1的消息内容,完全基于Task实现。
Task TCB数据结构里相关的定义如下:
typedef struct tskTaskControlBlock { ... #if( configUSE_TASK_NOTIFICATIONS == 1 ) volatile uint32_t ulNotifiedValue; volatile uint8_t ucNotifyState; #endif ... } tskTCB;Task Notifications的发送通知函数xTaskGenericNotify()
typedef enum { eNoAction = 0, //发送通知但不使用ulValue值,无通知内容 eSetBits, //被通知的任务的通知值按bit或ulValue eIncrement, //被通知的任务的通知值加1 eSetValueWithOverwrite, //被通知任务的通知值直接设置成ulValue,无论之前的通知值是否已经被读取 eSetValueWithoutOverwrite //之前的任务通知值被读取后,再更新被通知任务的通知值,如果没有读取则丢弃当前的ulValue } eNotifyAction; BaseType_t xTaskGenericNotify(...) { TCB_t * pxTCB; BaseType_t xReturn = pdPASS; uint8_t ucOriginalNotifyState; pxTCB = ( TCB_t * ) xTaskToNotify; taskENTER_CRITICAL(); { if( pulPreviousNotificationValue != NULL ) { //函数传入的参数,将ulNotifiedValue更新前的值赋值给这个传入参数,发送通知的task获得更新前的通知值 *pulPreviousNotificationValue = pxTCB->ulNotifiedValue; } //保存ucNotifyState ucOriginalNotifyState = pxTCB->ucNotifyState; //更新ucNotifyState pxTCB->ucNotifyState = taskNOTIFICATION_RECEIVED; //更新通知的方法,详见eNotifyAction枚举定义 switch( eAction ) { case eSetBits : pxTCB->ulNotifiedValue |= ulValue; break; case eIncrement : ( pxTCB->ulNotifiedValue )++; break; case eSetValueWithOverwrite : pxTCB->ulNotifiedValue = ulValue; break; case eSetValueWithoutOverwrite : if( ucOriginalNotifyState != taskNOTIFICATION_RECEIVED ) { pxTCB->ulNotifiedValue = ulValue; } else { xReturn = pdFAIL; } break; case eNoAction: break; } if( ucOriginalNotifyState == taskWAITING_NOTIFICATION ) { //被通知的任务正好在等待通知的状态,则将其添加到任务Ready List ( void ) uxListRemove( &( pxTCB->xStateListItem ) ); prvAddTaskToReadyList( pxTCB ); #if( configUSE_TICKLESS_IDLE != 0 ) { prvResetNextTaskUnblockTime(); } #endif if( pxTCB->uxPriority > pxCurrentTCB->uxPriority ) { //如果发现等待通知的任务优先级更高,则触发一次任务调度 taskYIELD_IF_USING_PREEMPTION(); } } taskEXIT_CRITICAL(); return xReturn; }从上面的源码可以看出任务通知的机制非常简洁,与任务本身相关,将相关的信息填写到任务TCB之后,判断等待通知的任务优先级是否更高,如果更高则直接触发一次任务调度。由此,可以理解任务只能等待在一个任务通知上,也可以获得长度为1的消息内容,这也有别于Semaphore/Queue等方式,但是简洁高效是其最大的特点,在某些场景下可以使用此方式。
中断处理函数里的任务通知函数与非中断保护的函数类似,只是增加了开关中断保护;而等待任务通知不能在中断中执行,等待通知函数ulTaskNotifyTake()和xTaskNotifyWait(),直接看xTaskNotifyWait()
BaseType_t xTaskNotifyWait(...) { BaseType_t xReturn; taskENTER_CRITICAL(); { //如果任务没有收到通知 if( pxCurrentTCB->ucNotifyState != taskNOTIFICATION_RECEIVED ) { pxCurrentTCB->ulNotifiedValue &= ~ulBitsToClearOnEntry; //将任务状态设置为等待通知状态 pxCurrentTCB->ucNotifyState = taskWAITING_NOTIFICATION; if( xTicksToWait > ( TickType_t ) 0 ) { //如果设置了阻塞等待超时时间,则将任务加入Delay List prvAddCurrentTaskToDelayedList( xTicksToWait, pdTRUE ); //触发任务调度 portYIELD_WITHIN_API(); } } } taskEXIT_CRITICAL(); //退出临界区,如果有任务调度,则任务被挂起 taskENTER_CRITICAL(); { if( pulNotificationValue != NULL ) { //通知值赋值给函数传入参数,返回给调用者 *pulNotificationValue = pxCurrentTCB->ulNotifiedValue; } if( pxCurrentTCB->ucNotifyState == taskWAITING_NOTIFICATION ) { //没有收到通知值,可能是阻塞等待超时或者阻塞等待超时为0,直接返回错误 xReturn = pdFALSE; } else { //收到了通知 pxCurrentTCB->ulNotifiedValue &= ~ulBitsToClearOnExit; xReturn = pdTRUE; } //重置状态为非等待通知状态 pxCurrentTCB->ucNotifyState = taskNOT_WAITING_NOTIFICATION; } taskEXIT_CRITICAL(); }Task Notifications基本就阅读完成了,简洁高效而且占用RAM少,可以实现轻量级Queue,Binary Semaphore, Semaphore和Event Groups,具有很高的效率优势,但是也要注意使用限制,只能有1个任务接收通知,发送通知的任务不能因为无法发送通知而进入阻塞状态。
-
RTOS学习笔记-FreeRTOS
FreeRTOS作为开源实时嵌入式操作系统,近几年RTOS使用量上一直名列前茅,《ARM学习笔记-STM32》中已经初步接触到了FreeRTOS的移植以及简单的使用,对FreeRTOS的深入学习可以通过FreeRTOS官网提供的资料继续学习,左侧导航栏从简介到Basic知识点再到Advanced进阶学习,FreeRTOS源码版本v9.0.0,平台选择STM32F4xx(ARM Cortex-M4)。
Basic
Tasks & Co-routines
FreeRTOS提供了Co-routines,中文名大家都称为协程,可以单独使用也可以与Task混合使用,Co-routines的stack是共享模式,不像每个tasks那样都有自己的单独的stack,主要是针对RAM非常稀缺的使用场景,目前32位的MCU应该不会再使用,因此先不对其做过多的深入,主要看tasks。Tasks其实都比较熟悉了,借用官网的状态图一展:
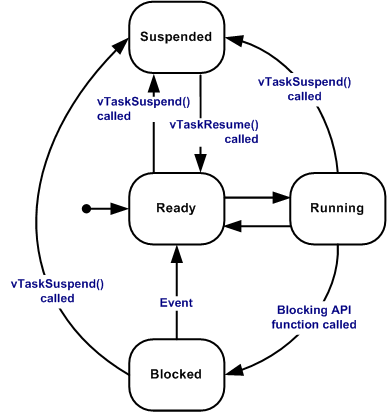
Tasks的优先级设置为0~(configMAX_PRIORITIES - 1),configMAX_PRIORITIES是在FreeRTOSConfig.h中配置的,这个宏定义不能随意定义,如果configUSE_PORT_OPTIMISED_TASK_SELECTION宏定义为1,则configMAX_PRIORITIES宏定义必须小于32,除此之外可以设置成任意值,但是configMAX_PRIORITIES的值越大,对RAM消耗越大,根据项目的需求设置成一个合理的值最佳。
configUSE_PORT_OPTIMISED_TASK_SELECTION宏定义针对某些处理器的特殊指令,如ARM Cortex-M的
CLZ(Count Leading Zeros)前导零计数指令,这条指令可以得到被操作的32bit数从高位起0的个数,如被操作数的bit[31] = 1,则返回的结果是0,如果操作数为0,返回结果为32,详见指令:CLZ{<cond>} <Rd>,<Rm> 指令伪代码: If Rm==0 Rd=32 Else Rd=31 - (bit position of most significant “1” in Rm)FreeRTOS里计算当前处于任务Ready队列里的最高优先级的任务:
/* Find the highest priority queue that contains ready tasks. */ #define portGET_HIGHEST_PRIORITY(uxTopPriority, uxReadyPriorities) uxTopPriority=(31-__clz((uxReadyPriorities)))由此也可以理解为什么使用这个指令优先级必须小于32。当然,这条指令还可以用于math计算等。
当前运行的task一般为满足运行条件的最高优先级任务。如果宏configUSE_TIME_SLICING未定义或定义为1,则相同优先级的任务之间采取时间片轮转调度。
Idle Task是FreeRTOS默认的最低优先级task,如果有其他任务也设置成了最低优先级,这个时候宏定义configIDLE_SHOULD_YIELD设置为1的作用是,如果其他的与idle task相同优先级的task处于了Ready状态,则idle task以最快的速度让另一个任务得到CPU并执行。但是,实际项目中Idle Task的作用更多的是考虑低功耗,因此一般都会将最低优先级保留给Idle Task。
Idle Task创建可以将宏定义configUSE_IDLE_HOOK设置为1,定义并实现Idle Task的钩子函数:
void vApplicationIdleHook( void );这个钩子函数是Idle Task流程中留给开发者实现的函数,开发者可以自定义在Idle Task里的执行内容,提醒开发者这个函数里面不可以有任何Block的操作,通过FreeRTOS的源码,task.c里面的static portTASK_FUNCTION(prvIdleTask, pvParameters)定义的Idle Task函数prvIdleTask的内容可以看到vApplicationIdleHook()的执行在tickless省电模式的前面,低功耗的流程在宏configUSE_TICKLESS_IDLE设置为非0的情况下执行,具体后面低功耗小节会详细介绍。
Queues,Semaphores,Mutexes
Queues用于tasks间的通讯,简单而灵活,发送到队列的消息是Copy进队列的,队列里做了缓存,这样tasks间的传递更加灵活,也可以传递指针,自定义消息数据结构和memory poll,对携带的消息格式和大小没有限制,一个队列可以接收各式消息,适用于MPU功能的场景,在发送消息时会提升MCU的权限,提升权限后就可以访问任意的存储区域,在中断处理函数中使用带
FromISR结尾的API。Semaphores与Mutexes:
- Semaphores分为Binary Semaphores和Counting Semaphores
- Mutexes分为Mutexes和Recursive Mutexes
- Semaphores用于任务间同步,tasks之间或者tasks与isr之间;Mutexes用于资源互斥,是保护某资源的token
- Semaphores在某个task或isr中give,在另一个中take;Mutexes要在某个task内take & give,Binary Semaphores也可类似使用。
- Mutexes具有优先级继承,当低优先级任务获得Mutexes运行时,自动将优先级升至与等待此Mutexes的最高优先级的任务一致,不能解决优先级反转问题,但是可以最大化的减少等待时间;Semaphores不具备此特性
- Semaphores与Mutexes的Create API不同,但是take/give的API相同,Mutex不能用于中断服务程序,没有带
FromISR结尾的API
Direct To Task Notifications
Task Notifications相较于Semaphores/Mutexes/Event Groups在解除阻塞上有明显的性能优势,官方给出的结论:
- 45% faster and uses less RAM 相较于Semaphores
- significant performance benefits 相较于Event Groups
通过宏定义configUSE_TASK_NOTIFICATIONS置为1打开Task Notifications功能。使用限制:
- 只能1个task接收Task Notifications
- 等待Task Notifications的task可以进入Blocked状态,但是发送Notifications的task不会因为无法立即发出Notifications而进入Blocked状态
Event Groups
宏定义configUSE_16_BIT_TICKS设置为1,则Event Groups具有8bit,如果设置为0,则有24bit。可以同时设置1或多个bit位,清除1或多个bit位,task进入Blocked状态等待某1个或多个bit位置位;event groups可以用于tasks的同步。
使用Event Groups的需要克服的条件:
- 避免产生race conditions。设置、测试和清除event bit是atomic原子操作
- 避免不确定性,event groups不知道有多少tasks因为event groups进入阻塞状态,也不知道event bit改变后有多少tasks会进入运行状态。因此在task里设置一个event bit时,FreeRTOS启动调度锁机制,确保中断使能状态;在isr内试图设置event bit时,启动中断延迟机制,推迟设置event bit的动作。
Example Code
Example在FreeRTOS源码里的路径是:FreeRTOS/Demo/Common/Minimal
Advanced
FreeRTOS宏定义
FreeRTOS宏定义主要分布在3个头文件中:
- FreeRTOSConfig.h //user application相关的设置
- FreeRTOS.h //内核相关的设置,如果user没有定义的宏在这里给出默认值
- portmacro.h //移植平台相关的宏定义
configUSE_PREEMPTION:设置为1,抢占式调度;0为协作式调度,即时间片轮转调度。一般都设置成1
configUSE_PORT_OPTIMISED_TASK_SELECTION:见上面Tasks里面有分析
configUSE_TICKLESS_IDLE:设置为1,低功耗tickless模式,即系统1ms节拍定时中断在低功耗时停止,唤醒校正后继续,这样做的主要考虑是节拍中断频率过高也带来过多的功耗;设置为0则节拍中断持续不关断。关于低功耗后面还有专门的学习
configUSE_IDLE_HOOK:见上面Idle Task,设置为1启用idle task的hook函数,idle task的工作,设置为0不启用
configUSE_MALLOC_FAILED_HOOK:分配内存失败,malloc返回NULL时,调用的hook函数,前提需要用户在移植FreeRTOS后,使用堆方案为FreeRTOS提供的heap_1~5.h中的任意一个方案。设置为1需调用,用户需要定义;设置为0不需要调用。函数原型:
void vApplicationMallocFailedHook(void);configUSE_DAEMON_TASK_STARTUP_HOOK:默认设置为0
configUSE_TICK_HOOK:设置为1,在节拍中断的处理函数里面会执行这个hook函数,设置为0则不执行。一般没什么需要设置为0。函数原型:
void vApplicationTickHook(void);configCPU_CLOCK_HZ:写入正确的系统时钟频率,后面相应的时钟节拍也要基于此计算
configTICK_RATE_HZ:时钟节拍频率,即1秒钟多少拍,一般设置为1000
configMAX_PRIORITIES:设置有效任务优先级的最大数,详见上面Tasks里有详细介绍
configMINIMAL_STACK_SIZE:设置Idle Task的堆栈大小,一般以word为单位
configMAX_TASK_NAME_LEN:创建Task时,描述Task名字字符串长度
configUSE_TRACE_FACILITY:设置为1启动可视化跟踪调试,附加一些额外的数据结构和函数。STM32CubeMx工程里默认直接设置1
configUSE_STATS_FORMATTING_FUNCTIONS:配合前面的configUSE_TRACE_FACILITY / configGENERATE_RUN_TIME_STATS设置为1,而其也设置为1,则会打开几个函数(详见源码,默认设置为0):
static char *prvWriteNameToBuffer(char *pcBuffer, const char *pcTaskName) void vTaskList(char * pcWriteBuffer) void vTaskGetRunTimeStats(char *pcWriteBuffer)configUSE_16_BIT_TICKS:时钟节拍计数器变量类型,设置为1则portTickType为16bit,而设置为0则为32bit,STM32设置成32bit,时钟计数器的最大时钟计数更大。
configIDLE_SHOULD_YIELD:详见Idle Task里的说明
configUSE_TASK_NOTIFICATIONS:设置为1则包含使能Task Notifications,设置为0则不包含,是能后每个Task额外多使用8个Bytes的RAM。新特性,是FreeRTOS解除task阻塞状态最快的方式。设置为1
configUSE_MUTEXES:设置为1包含使用Mutexes,设置为0则不包含使用
configUSE_RECURSIVE_MUTEXES:同上对Recursive Mutexes设置
configUSE_COUNTING_SEMAPHORES:同上对Counting Semaphores的设置
configCHECK_FOR_STACK_OVERFLOW:详见后面关于栈溢出的学习
configQUEUE_REGISTRY_SIZE:主要用于FreeRTOS内核调试,队列记录的2个目的:(1)GUI调试的时候用队列文本名简单的识别队列(2)包含调试器需要的Queues或Semaphores的记录信息。除了FreeRTOS内核调试之外没有任何其他的目的,此值定义最大记录长度,STM32F4xx里面默认设置成8
configUSE_QUEUE_SETS:设置成1使能queue set功能,0则不使能。默认设置为0
configUSE_TIME_SLICING:详见Task里的说明,默认设置成1
configUSE_NEWLIB_REENTRANT:设置为1则newlib reent数据结构在创建task时allocated,FreeRTOS默认不使用,需要user自己决定是否使用,并能完全掌握newlib的情况下自行使用。
configENABLE_BACKWARD_COMPATIBILITY:为了兼容v8.0.0之前的版本定义的一些宏,没有历史包袱可以不打开这个宏
configNUM_THREAD_LOCAL_STORAGE_POINTERS:详见后面关于Thread Local Storage Pointers的学习,默认为0
configSUPPORT_STATIC_ALLOCATION:默认为0,RTOS的对象只能在RTOS的heap上分配;设置成1,则需要用户提供额外的回调函数提供memory,vApplicationGetIdleTaskMemory和vApplicationGetTimerTaskMemory。详见后面的学习内容
configSUPPORT_DYNAMIC_ALLOCATION:默认设置为1,RTOS对象在RTOS heap的RAM里分配;设置为0需要通过回调函数提供额外memory。同上见后面的学习内容
configTOTAL_HEAP_SIZE:上面的宏设置为1,这个宏设置堆大小,STM32F4xx默认设置为15K
configAPPLICATION_ALLOCATED_HEAP:默认为0,如果设置为1,需要user自定义heap数组:
uint8_t ucHeap[ configTOTAL_HEAP_SIZE ];configGENERATE_RUN_TIME_STATS:默认为0,详见后面Run Time Stats
configUSE_CO_ROUTINES:默认为0,与co-routines相关
configMAX_CO_ROUTINE_PRIORITIES:STM32F4xx默认为2,32位MCU一般不用Co-routines
configUSE_TIMERS:默认为0,不打开Software Timers功能;1则不打开
configTIMER_TASK_PRIORITY:如果上面的宏打开,则需要设置
configTIMER_QUEUE_LENGTH:同上
configTIMER_TASK_STACK_DEPTH:同上
configKERNEL_INTERRUPT_PRIORITY & configMAX_SYSCALL_INTERRUPT_PRIORITY & configMAX_API_CALL_INTERRUPT_PRIORITY: 这几个宏比较关键,移植工作中需要小心关注,与平台相关性大。总终配置还是以ARM Cortex-M4内核为例,详见RTOS-Cortex-M3-M4介绍。
Coretex-M4需要配置configKERNEL_INTERRUPT_PRIORITY和configMAX_SYSCALL_INTERRUPT_PRIORITY,而configMAX_API_CALL_INTERRUPT_PRIORITY与configMAX_SYSCALL_INTERRUPT_PRIORITY等价,主要是应用于不同的平台移植时的兼容性上。
Cortex-M系列的中断机制与FreeRTOS配合非常紧密,但是各家的Cortex-M处理器在中断优先级寄存器的设计上不尽相同,Cortex-M最多允许256级可编程优先级,寄存器8bit,配置范围(0~0xff),不过STM32F4xx系列使用了4bit,所以范围是(0~0xf),共16级可编程优先级。这里还要注意一点,ARM的中断优先级是数字越低,优先级越高,最高优先级是0,而与一般的逻辑优先级的概念刚好与此相反。STM32F4xx系列优先级寄存器是4bit,占用的是8bit寄存器的高4bit,如下图所示,优先级5在寄存器中的配置,其他不使用的位全部置为1:

这样就能更好的理解FreeRTOS里面的配置(STM32F4xx Cortex-M4):
/* Cortex-M specific definitions. STM32F4xx use high 4bit to register interrupt priority*/ #define configPRIO_BITS 4 /* The lowest interrupt priority that can be used in a call to a "set priority" function. */ #define configLIBRARY_LOWEST_INTERRUPT_PRIORITY 15 /* The highest interrupt priority that can be used by any interrupt service routine that makes calls to interrupt safe FreeRTOS API functions. DO NOT CALL INTERRUPT SAFE FREERTOS API FUNCTIONS FROM ANY INTERRUPT THAT HAS A HIGHER PRIORITY THAN THIS! (higher priorities are lower numeric values. */ #define configLIBRARY_MAX_SYSCALL_INTERRUPT_PRIORITY 5 /* Interrupt priorities used by the kernel port layer itself. These are generic to all Cortex-M ports, and do not rely on any particular library functions. */ #define configKERNEL_INTERRUPT_PRIORITY (configLIBRARY_LOWEST_INTERRUPT_PRIORITY << (8 - configPRIO_BITS)) /* !!!! configMAX_SYSCALL_INTERRUPT_PRIORITY must not be set to zero !!!! See http://www.FreeRTOS.org/RTOS-Cortex-M3-M4.html. */ #define configMAX_SYSCALL_INTERRUPT_PRIORITY (configLIBRARY_MAX_SYSCALL_INTERRUPT_PRIORITY << (8 - configPRIO_BITS))configKERNEL_INTERRUPT_PRIORITY一般配置成平台的最低优先级,FreeRTOS 内核就运行在这个优先级,configMAX_SYSCALL_INTERRUPT_PRIORITY配置为高优先级上限,这里配置成了5,那么更高的优先级(0~4)就被保留变成FreeRTOS不可屏蔽的中断优先级,这些更高优先级的中断里就不可以再调用FreeRTOS API,也完全不会受到FreeRTOS内核的影响,具有非常高的实时性,而中断优先级(5~15)就可以完全被FreeRTOS托管,应用程序应该使用这个中断优先级区间的优先级。
configASSERT:断言的定义,开发阶段打开,release后可以关闭,不关闭会增大代码空间,带来性能损失。
configINCLUDE_APPLICATION_DEFINED_PRIVILEGED_FUNCTIONS:默认为0,此宏定义仅与MPU功能相关,在开发阶段使用,release阶段需关闭。
INCLUDE_xxx:以此前缀开头的宏用于决定是否将此API编译进项目工程,设置为1则进行编译,设置为0表示不编译。
Low Power Support
FreeRTOS默认已经实现了Idle Task,并在Idle Task里也给出了低功耗的流程,需要开发者添加一些自己应用场景相关的一些操作即可使用,其他就是一些宏开关的设置。官方给出的低功耗解读请参考low-power-tickless-rtos,而与ARM Cortex-M系列相关的请参考low-power-ARM-CortexM-rtos
FreeRTOS用宏configUSE_TICKLESS_IDLE控制系统是否进入Tickless Idle Mode,FreeRTOS使用一个定时器产生操作系统Tick,一般设置为1ms产生1个Tick中断,如果系统进入低功耗以后,依然产生这个1ms中断,假如很长一段时间都没有高优先级任务需要执行,那么这1ms中断频繁从低功耗模式醒来也会带来很可观的功耗,因此有了这个Tickless模式。Tickless模式的原理就是进入低功耗前关闭1ms的中断,而是设置一个本次低功耗的阈值,无论是这个阈值时间到了从低功耗被唤醒,还是被其他的中断或事件唤醒,再重新启动1ms中断和修正操作系统的TickCount值,以此来达到低功耗情况下尽可能少的被唤醒,也是一种更好的省电策略。
configUSE_TICKLESS_IDLE被置为1,FreeRTOS就可以在系统空闲并进入Idle Task之后进入到Tickless的处理流程,Idle Task里的源码在task.c里面:
#if ( configUSE_TICKLESS_IDLE != 0 ) ... //开发者自定义,增加此时的trace调试相关 traceLOW_POWER_IDLE_BEGIN(); //port.c中定义了Tickless低功耗的具体实现 portSUPPRESS_TICKS_AND_SLEEP( xExpectedIdleTime ); //开发者自定义,增加此时的trace调试相关 traceLOW_POWER_IDLE_END(); ... #endif /* configUSE_TICKLESS_IDLE */关键Tickless低功耗模式参见port.c里的源码:
__weak void vPortSuppressTicksAndSleep( TickType_t xExpectedIdleTime ) { uint32_t ulReloadValue, ulCompleteTickPeriods, ulCompletedSysTickDecrements, ulSysTickCTRL; TickType_t xModifiableIdleTime; //ARM Systick提供Tick,Systick寄存器24bit,与Core时钟同频 //FreeRTOSConfig.h configSYSTICK_CLOCK_HZ=configCPU_CLOCK_HZ //确保Systick的赋值不会溢出 if( xExpectedIdleTime > xMaximumPossibleSuppressedTicks ) { xExpectedIdleTime = xMaximumPossibleSuppressedTicks; } //停止Systick portNVIC_SYSTICK_CTRL_REG &= ~portNVIC_SYSTICK_ENABLE_BIT; //计算Systick的Reload Tick数 ulReloadValue = portNVIC_SYSTICK_CURRENT_VALUE_REG + ( ulTimerCountsForOneTick * ( xExpectedIdleTime - 1UL ) if( ulReloadValue > ulStoppedTimerCompensation ) { ulReloadValue -= ulStoppedTimerCompensation; } //进入临界区 //不使用taskENTER_CRITICAL()因其会退出省电模式 __disable_irq(); __dsb( portSY_FULL_READ_WRITE ); __isb( portSY_FULL_READ_WRITE ); //如果不符合进入低功耗的条件,暂时先不进低功耗 if( eTaskConfirmSleepModeStatus() == eAbortSleep ) { portNVIC_SYSTICK_LOAD_REG = portNVIC_SYSTICK_CURRENT_VALUE_REG; portNVIC_SYSTICK_CTRL_REG |= portNVIC_SYSTICK_ENABLE_BIT; portNVIC_SYSTICK_LOAD_REG = ulTimerCountsForOneTick - 1UL; __enable_irq(); } else //进入低功耗的处理流程 { //Systick设置成重载的值,即预期进入低功耗的计算出的合适的阈值 portNVIC_SYSTICK_LOAD_REG = ulReloadValue; portNVIC_SYSTICK_CURRENT_VALUE_REG = 0UL; portNVIC_SYSTICK_CTRL_REG |= portNVIC_SYSTICK_ENABLE_BIT; xModifiableIdleTime = xExpectedIdleTime; //开发者可以在下面这个宏定义自己的低功耗处理方式 //而不用执行下面默认的进入低功耗的流程 //也可以在这个宏定义里添加其他时钟/电源/外设的处理 configPRE_SLEEP_PROCESSING( xModifiableIdleTime ); if( xModifiableIdleTime > 0 ) { __dsb( portSY_FULL_READ_WRITE ); __wfi(); //WFI指令进入ARM的Sleep模式,任意中断可以唤醒 __isb( portSY_FULL_READ_WRITE ); } configPOST_SLEEP_PROCESSING( xExpectedIdleTime ); ulSysTickCTRL = portNVIC_SYSTICK_CTRL_REG; portNVIC_SYSTICK_CTRL_REG = ( ulSysTickCTRL & ~portNVIC_SYSTICK_ENABLE_BIT ); __enable_irq(); //计算FreeRTOS的Tick计数的补偿值 if( ( ulSysTickCTRL & portNVIC_SYSTICK_COUNT_FLAG_BIT ) != 0 ) { //Systick计时到了产生的中断唤醒情况下的补偿计算 ... } else { //其他中断唤醒情况下的补偿计算,此时Systick计时未到 ... } //更新FreeRTOS的Tick计数xTickCount,启动Systick的1ms的Tick中断 portNVIC_SYSTICK_CURRENT_VALUE_REG = 0UL; portENTER_CRITICAL(); { portNVIC_SYSTICK_CTRL_REG |= portNVIC_SYSTICK_ENABLE_BIT; vTaskStepTick( ulCompleteTickPeriods ); portNVIC_SYSTICK_LOAD_REG = ulTimerCountsForOneTick - 1UL; } portEXIT_CRITICAL(); } }以上就是FreeRTOS默认的低功耗处理流程,系统使用ARM Cortex-M提供的Systick定时器产生Tick时钟,1ms中断,进入低功耗后停止Systick的1ms中断,重新加载一个更长的时间周期,这个期间FreeRTOS的Tick计数也不更新了,系统唤醒后再重新开启Systick的1ms中断,并补偿休眠期间RTOS的Tick计数。很多开发者为了达到更加省电的目的,期望有更长的睡眠时间,即上面Systick的加载值更大,但是Systick是24Bit的(最大值0xffffff),而且其使用的时钟频率与Core相同(160MHz),因此由这2个参数就决定了低功耗使用Systick计时的每次休眠时间有一个上限值,大约100ms,睡眠周期太短,开发者就会考虑使用其他定时器替代Systick,如32Bit的定时器(最大值0xffffffff),这样上限值就扩大到了25s左右。再激进一点,如果在进入低功耗的时候,采用一个32Bit定时器而且是低频率的在睡眠期间做计时,醒来后再重新开启Systick和补偿RTOS计数,是不是就能够获得更长的睡眠周期^_^
FreeRTOS针对ARM Cortex-M也给出了相应说明,Systick定时器是FreeRTOS默认的为ARM Cortex-M处理器提供Tick中断的24Bit定时器,其Systick工作频率:
- 可以与Core同频,FreeRTOSConfig.h里设置宏configSYSTICK_CLOCK_HZ与configCPU_CLOCK_HZ相同【默认】
- 为了获得更长的休眠周期,也可以与Core不同频,单独设置宏configSYSTICK_CLOCK_HZ为Systick的时钟频率
FreeRTOS从v7.3.0版本之后,支持开发者可以不使用Systick定时器而改用其他定时器为RTOS提供Tick中断:
- 重新定义函数void vPortSetupTimerInterrupt(void),替换成其他定时器产生RTOS的Tick中断,这个函数在vTaskStartScheduler()调用时被调用,初始化定时器并使能Tick中断,Tick周期参照宏configTICK_RATE_HZ定义。另外注意configOVERRIDE_DEFAULT_TICK_CONFIGURATION设置为1,原来的vPortSetupTimerInterrupt()就被注释掉,需要同名再创建一个新的函数
- 相应的新定时器的中断处理函数也要定义,默认Systick的中断处理函数是xPortSysTickHandler()
- 注意CMSIS标准命名SysTick_Handler(),在启动文件*.s汇编文件里用的这个命名为RTOS的Tick中断处理函数,使用新的定时器为RTOS提供Tick,不要与Systick定时器的中断处理程序搞混了,特别是命名上需要注意
在执行WFI指令前后的两个宏定义如下,可以在前面一个宏定义里增加更多节约功耗的操作,如关闭外设,切换时钟,关闭电源等;也可以设置xExpectedIdleTime为0,不走接下来的进低功耗的流程,而自定义低功耗流程。后面一个宏定义是从低功耗退出后的处理,与前面的宏对应
- configPRE_SLEEP_PROCESSING(xExpectedIdleTime)
- configPOST_SLEEP_PROCESSING(xExpectedIdleTime)
下面是一些配置示例总结:
- 默认的低功耗机制,Systick定时器,频率与CPU Core同频,Tickless模式,设置宏USE_TICKLESS_IDLE=1
- Systick定时器,频率与CPU Core不同频,Tickless模式,设置USE_TICKLESS_IDLE=1,设置configSYSTICK_CLOCK_HZ为实际时钟频率
- 不使用Systick,而使用其他定时器产生RTOS的Tick中断,设置宏USE_TICKLESS_IDLE=2,自定义新定时器初始化函数vPortSetupTimerInterrupt(),设置宏configTICK_RATE_HZ,定义相应的xPortSysTickHandler(),新定时器的中断处理函数,同时注意CMSIS命名,不要与SysTick_Handler()产生冲突
- 使用现有的机制,只是将Systick替换成其他的定时器,目前FreeRTOS还没有相关的配置
FreeRTOS的低功耗机制已经基本学习完毕,结合ARM Cortex-M的低功耗,可以看出FreeRTOS的低功耗使用的是ARM的Sleep模式,通过STM32F4xx的参考手册(Cortex-M4),可以了解到其提供了3种低功耗模式,详见图示:
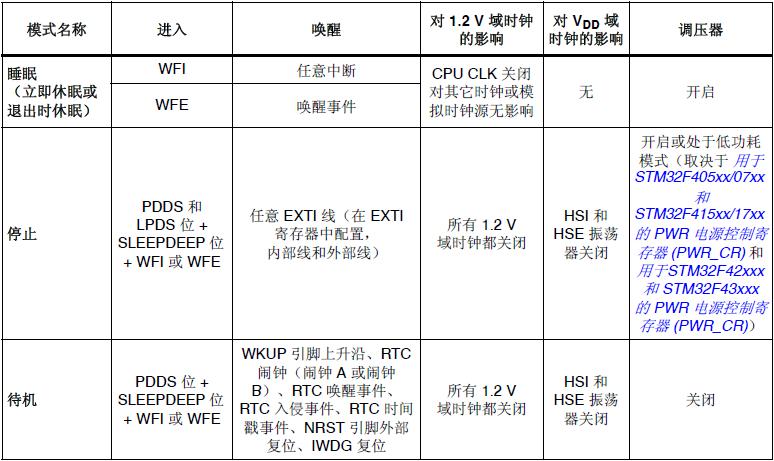
FreeRTOS里默认使用的是Sleep模式,还有2种分别是Stop模式和Standby模式。Standby模式是深度睡眠模式,最省电,但是一旦进入到这种低功耗模式,除了备份域(RTC与备份RAM)和待机电路寄存器外,寄存器和RAM中的内容全部Reset,基本可以理解为唤醒系统后软件从头运行,这种模式虽然省电,但是不适合应用在RTOS里面。再看一下Stop模式,进入这种模式的低功耗,1.2V电压域中的时钟全部停止,PLL/HSI/HSE RC振荡器也被禁止,内部SRAM和寄存器的内容会全部保留,但是在被唤醒之后,会有一个延迟,需要恢复时钟/恢复Flash的时间,如果使用调压器调压,也需要时间,这种模式也可以应用到RTOS里,但是,如果系统对实时性要求比较高,这样的省电模式就得慎重考虑如何使用了,还需要注意的一个问题是,当进入这种模式的低功耗之后,需要有一个在此时运行的定时器继续运行,在系统醒来之后进行计时补偿,如RTC。关于这几种功耗模式的使用,可以去参考标准固件库或者CubeMx固件库里的Examples。
Memory Management
FreeRTOS提供了5种堆内存分配管理文件,详见源码Source/Portable/MemMang下面的5个heap_x.c文件,每一种都代表了1种应用场景,开发者可以自己选择使用哪一种,或者替换成自定义的。
- heap_1.c
堆内存管理中最简单的一个,只能申请分配内存,一旦申请成功不能释放,不会产生内存碎片,特别适合对安全要求高的场景。
在整片的堆内存上按照顺序依次获得需要大小的内存,xNextFreeByte用来记录已经分配的堆内存大小,(configADJUSTED_HEAP_SIZE - xNextFreeByte)计算剩余的堆内存,这里还要注意一个问题就是地址对齐,提高MCU的内存访问效率,STM32F4xx(Cortex-M4)的宏定义portBYTE_ALIGNMENT=8,即8字节对齐。
- heap_2.c
相比heap_1可以释放分配的堆内存,但是不会进行内存碎片整理,如果在使用堆内存时,如task/queue等每次用到的内存size是相同的,而不是变化不可确定的,打个比方如创建task需要分配内存,而所有的task创建时分配的内存大小相同,其他如Queue等也是如此,就可以使用这种方案,否则建议使用heap_4.c
heap_1分配可以看成是对数组的操作,heap_2允许释放内存,就需要使用链表的数据结构,定义如下:
typedef struct A_BLOCK_LINK { struct A_BLOCK_LINK *pxNextFreeBlock; /*<< The next free block in the list. */ size_t xBlockSize; /*<< The size of the free block. */ } BlockLink_t;维护了一个可分配堆内存块的单向链表,而且是按照可分配堆内存的大小升序排列的,初始化时xStart是链表头,指向第一个可分配堆内存块,xEnd用作链表尾:
升序单向链表: xStart -> Free_Node_1 ... -> Free_Node_n -> xEnd 升序排列条件:(Free_Node_1.xBlockSize < Free_Node_n.xBlockSize) xStart与xEnd为单独定义的链表节点,Free_Node_x都是堆内存里存储的节点 每个内存块在堆内存中的存储格式: |------------------| |BlockLink_t | | ->pxNextFreeBlock| | ->xBlockSize | |------------------| | | | | | 对应xBlockSize的 | | 可分配的内存区 | | | | | |------------------|Malloc()时从链表头开始寻找,找到第一个满足size的Free堆内存块,将此内存块从这个可分配的堆内存块的链表中移除,如果满足条件的内存块较大,则分裂成2个,前一个正好满足需求的大小,剩余的全部分给新的内存块,然后将这个内存块插入到可分配堆内存块的链表里。Free()时直接将内存块插入到链表里。使用xFreeBytesRemaining保存剩余的可分配的内存大小。
- heap_3.c
封装了标准C库里的malloc()和free(),需要在编译器里指定堆内存,宏定义configTOTAL_HEAP_SIZE对其不起作用。
- heap_4.c
Malloc()时使用first fit算法,不像heap_2那样按照大小升序排列后找到size刚好匹配的那个,heap_4是按照地址前后排列的,malloc()时找到第一个合适大小的内存就分配,malloc()和free()中将相邻的Free的内存块合并成更大的Free内存块,更适合不确定大小的内存分配使用场景。
数据结构还是单链表,其定义与heap_2相同,还是维护一个可分配堆内存的链表,但不是升序排列,而是按地址前后顺序。初始化后xStart还是链表头,与之前相同都是指向第一个可分配的堆内存块,xEnd还是链表尾,但是存储在堆内存尾部,xFreeBytesRemaining还是保存剩余的可分配的内存大小,新增了2个变量,xMinimumEverFreeBytesRemaining用于保存当前可分配的堆内存块的最小size,xBlockAllocatedBit用于标记数值的最高位为1,如32bit的MCU,其值为0x80000000,在算法中与BlockLink_t->xBlockSize进行与or或操作,用于标示此内存块是否是Free可以分配的。
Malloc()还是遍历链表,找到第一个大小合适的内存就分配,如果此内存块更大,则分裂成两个节点,然后将Free的那个节点插入到可分配堆内存链表里,此链表节点按照地址先后顺序排列,每次寻找到合适的地址插入点,判断是否可以与前后节点合并成一个节点,然后进行合并或者插入链表,然后更新xFreeBytesRemaining、xFreeBytesRemaining,xBlockAllocatedBit操作。Free()也是完成上面的插入链表的操作。内存块合并操作在插入链表的过程中完成,相邻地址合并原则。
- heap_5.c
同样使用了heap_4中的first fit和内存块合并算法,不同的是heap_5应对的是堆内存分布在不连续的区域上的情况,如:
/* Used by heap_5.c. */ typedef struct HeapRegion { uint8_t *pucStartAddress; size_t xSizeInBytes; } HeapRegion_t; const HeapRegion_t xHeapRegions[] = { { ( uint8_t * ) 0x80000000UL, 0x10000 }, { ( uint8_t * ) 0x90000000UL, 0xa0000 }, { NULL, 0 } /* Terminates the array. */ };首先要对堆内存区域进行初始化,详见下面的初始化函数:
void vPortDefineHeapRegions(const HeapRegion_t * const pxHeapRegions)初始化函数就是将所有的堆内存块用链表链接起来,每一块地址连续的堆内存块格式如下:
|------------------| |BlockLink_t | | ->pxNextFreeBlock| | ->xBlockSize | |------------------| | | | | | 对应xBlockSize的 | | 可分配的内存区 | | | | | |------------------| |BlockLink_t | | ->pxNextFreeBlock| | ->xBlockSize=0 | |------------------|然后将所有的堆内存块链接起来,相应的变量初始化好后,初始化工作就完成了。剩下的就与heap_4的使用完全相同了,完全看成是待分配的Free堆内存链表,只是不连续的区域可以认为是已经被分配的内存(永远不会被释放回来),其Malloc()/Free()以及相应的链表插入操作与heap_4完全相同。
Stack Usage and Stack Overflow Checking
Task Stack检查功能,通过宏定义configCHECK_FOR_STACK_OVERFLOW开启栈溢出检查功能,在vTaskSwitchContext()时做栈溢出检查,FreeRTOS提供了2种栈溢出检查方法,开发者需要自定义hook函数vApplicationStackOverflowHook(),栈溢出后再此函数内添加开发者自己的调试信息,此功能在开发和测试阶段使用。
- configCHECK_FOR_STACK_OVERFLOW=1
此方法检查栈地址是否越界来判断是否栈溢出,此方法速度快,但是在task运行时已经栈溢出,出栈后栈指针又回到正常范围内,就无法检测到了。
- configCHECK_FOR_STACK_OVERFLOW=2 (目前只要大于1)
此方法在task初始化时将整个栈初始化为特定值0xa5a5a5a5,检查最后16个byte是否被修改成其他值的方法来判断是否发生栈溢出,相比第一种方法是慢一些,但是确实避免了上面检测不到的情况。
关于Stack Overflow & Detecting的方法还有很多,还可以参看uC/OS的一些方法总结。使用MCU特定的栈指针地址保护(访问到某段地址就会产生Exception中断),或者利用Cortex-M的MPU功能做地址保护,访问到被保护的地址产生Exception中断,或者利用软中断等方法。这样做的好处是在Task运行时就能够判断出是否栈溢出了,一旦发生栈溢出会产生Exception中断。
Others
FreeRTOS还提供了很多有用的功能、Demo和资料:
- Trace Features,在RTOS里很多关键的位置预留了trace调试接口
- Run Time Statistics,配置一个比RTOS的Tick定时器快10~100倍的定时器,调用接口得到如Tasks Run Time百分比统计信息等
- Porting Guide移植工作指导
- Windows Simulator/Posix/Linux Simulator模拟器相关
- How FreeRTOS Works基于AVR平台由浅入深的介绍FreeRTOS工作原理
- Memory Protection SupportMPU支持
- API详细介绍
- Supported Devices & Demos列出了FreeRTOS目前支持的芯片厂家及其产品系列
- Demo Projects列出了一些典型的Demo工程
小结
主要以FreeRTOS官网提供的资料为主,结合ARM Cortex-M,对一些主要功能进行了深入的理解,没有对FreeRTOS的API使用和构建应用进一步的深入,从应用层角度使用RTOS是基本类似的,也是比较容易上手的部分,需要的时候直接查看官方文档。
-
ARM学习笔记-STM32
物联网以及智能硬件领域的微控制器,ARM Cortex-M系列无疑是首选,刚好最近从朋友处拿到一块STM32F4系列的开发板(NUCLEO STM32F412ZGT6),学习一下。
STM32
STM32是意法半导体制作的基于自家设计的ARM Cortex-M内核处理器的评估开发板,提供了丰富的文档、开发工具以及开发示例,完善的社区支持,并且支持大量的扩展版,可以快速的构建产品原型,加快后续产品化。意法半导体还提供了stm32CubeMx软件,旨在最大化的减轻开发工作,通过此软件可以选择不同的处理器,解决引脚冲突,配置时钟树,设置外围外设,选择RTOS,选择中间件(USB/TCP/IP等),生成面向IAR/KEIL/GCC的不同的软件工程。总之,最大化消除硬件平台差异化带来的改动,最大程度减轻构建软件工程的时间,让开发者更好的集中在自己产品的原型构建上。
软件开发环境
ARM的软件开发环境基本可以分为3种:
- ARM自家的集成开发环境ARM MDK,收购KEIL之后推出
- 瑞典的国宝级软件IAR
- GCC,开源的不二选择,可以linux命令行使用也可以结合Eclipse使用,桌面版集成开发环境请参考openSTM32/TrueSTUDIO
先来看一下ARM自家的MDK,目前国内用的最多,资料丰富;GCC在后面的ARM+Linux(或Android)会用到;IAR与openSTM32暂时先搁置一下,有时间再看,先看最典型的两种。
目前ARM MDK与IAR都不是免费的,国内使用大家按照默认规则就好了,Google或百度基本都能搞定,ARM MDK安装版本v5.23,操作系统需要Win7以上。
STM32开发板支持ST-Link/V2-1加载调试仿真,已经成为标配,只需要一根手机充电线(即USB线)连接开发板与PC,不需要再额外购买调试仿真器(其他常用的是JLINK和ULINK)。需要在PC上安装ST-Link/V2-1 USB驱动v1.01。使用ST-Link/V2-1还需要在ARM MDK中配置使用ST-Link,稍后调试使用时再详细介绍。
官方标准固件库和软件包
STM32F4系列的官方标准固件库可以从STM32中文官网下载v1.8.0。
解压缩标准固件开发包,可见目录结构:
_htmresc Libraries\ \\库文件,创建工程时用到 |-CMSIS \\ARM控制器软件接口标准文件 |-STM32F4xx_StdPeriph_Driver \\标准外设驱动,基于CMSIS Projects\ |-STM32F4xx_StdPeriph_Examples \\标准固件例程 |-STM32F4xx_StdPeriph_Templates \\创建项目工程模板 Utilities\ \\例程中用到的一些工具资源 |-Media |-ST |-STM32_EVAL |-Third_Party MCD-ST***.pdf Release_Notes.html stm32fxx_dsp_stdperiph_lib_um.chm //整个开发包说明文档由于我们使用的工具是MDK,可以进入Projects\STM32F4xx_StdPeriph_Templates\
Projects\STM32F4xx_StdPeriph_Templates\ |-EWARM\ \\IAR工程 |-MDK-ARM\ \\MDK工程 |-SW4STM32\ \\SW4STM32工程 |-TrueSTUDIO\ \\TrueSTUDIO工程 |-main.c |-main.h |-stm32f4xx_config.h |-stm32f4xx_it.c |-stm32f4xx_it.h |-system_stm32f4xx.c |-Release_Notes.html |-readme.txt \\关键信息!!!首先阅读
readme.txt,里面都已经写得很详细了,先看“How to use it ?”,直接看MDK-ARM那段,是对如何使用MDK工程的说明,其他工具用到后再看:+ MDK-ARM -Open the Template.uvprojx project -Rebuild all files: Project->Rebuild all target files -Load project image: Debug->Start/Stop Debug Session -Run program: Debug->Run (F5)而Templates目录下的
*.h和*.c文件即为标准固件包里的例程,即Projects\STM32F4xx_StdPeriph_Examples\下面关于各个模块的标准例程,将其copy到此Templates目录下,再使用相应的工程来编译加载调试运行。具体可以参看每个例程的readme.txt文件,都有如何使用此例程的详细说明。以Projects\STM32F4xx_StdPeriph_Examples\ADC\ADC_DMA\为例:Projects\STM32F4xx_StdPeriph_Examples\ADC\ADC_DMA\ |-main.c |-main.h |-stm32f4xx_config.h |-stm32f4xx_it.c |-stm32f4xx_it.h |-system_stm32f4xx.c阅读
readme.txt文件:Example Description \\关于此例程的总体说明 ... Directory contents \\目录文件说明 -system_stm32f4xx.c STM32F4xx system clock configuration file -stm32f4xx_conf.h Library Configuration file -stm32f4xx_it.c Interrupt handlers -stm32f4xx_it.h Interrupt handlers header file -main.c Main program -main.h Main program header file How to use it ? \\如何使用此例程,copy到模板目录中,还有额外的Utilities中的文件也要被用到 In order to make the program work, you must do the following: -Copy all source files from this example folder to the template folder under Project\STM32F4xx_StdPeriph_Templates -Open your preferred toolchain -Select the project workspace related to the used device -If "STM32F40_41xxx" is selected as default project Add the following files in the project source list: -Utilities\STM32_EVAL\STM3240_41_G_EVAL\stm324xg_eval.c -Utilities\STM32_EVAL\STM3240_41_G_EVAL\stm324xg_eval_lcd.c -Utilities\STM32_EVAL\STM3240_41_G_EVAL\stm324xg_eval_fsmc_sram.c -Utilities\STM32_EVAL\STM3240_41_G_EVAL\stm324xg_eval_ioe.c -Rebuild all files and load your image into target memory -Run the examplereadme.txt文件已经非常详细的说明了例程结合模板工程如何使用了,其他例程就都会用了,下面我们按照工程模板中的readme.txt说明,打开MDK工程并编译运行加载默认的例程。双击MDK工程文件 Projects\STM32F4xx_StdPeriph_Templates\MDK-ARM\Project.uvprojx:
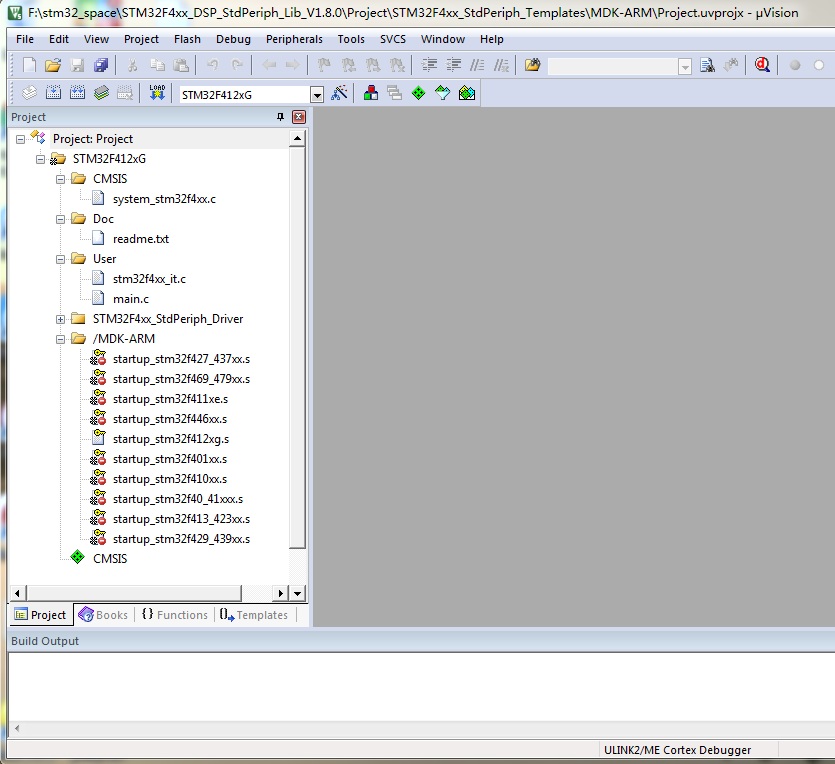
从左侧
Project栏里的目录结构看,CMSIS和MDK-ARM目录下的system_stm32f4xx.c和startup_stm32f412xg.s都是标准固件库STM32F4xx_DSP_StdPeriph_Lib_V1.8.0提供的,位于标准Libraries\CMSIS\Device\ST\STM32F4xx\Source\Templates目录下,是符合ARM CMSIS软件接口标准的,startup_stm32f412xg.s是ARM MDK环境下的启动文件,汇编语言编写,摘录一段:Reset_Handler PROC EXPORT Reset_Handler [WEAK] IMPORT SystemInit IMPORT __main LDR R0, =SystemInit BLX R0 LDR R0, =__main BX R0 ENDP先执行
SystemInit函数,SystemInit函数实现就在system_stm32f4xx.c里,初始化系统时钟/PLL/Flash接口等,然后再跳转到main函数。SystemInit函数名的定义也是符合CMSIS软件接口标准的,另外在标准固件库里面Libraries\CMSIS\Device\ST\STM32F4xx\Include\还有2个头文件stm32f4xx.h和system_stm32f4xx.h,其中stm32f4xx.h是寄存器相关的定义,而system_stm32f4xx.h则是SystemInit函数的头文件。至此,符合CMSIS的两个*.c和两个*.h文件基本就清楚了,在任何一个工程里都少不了这几个文件,而且ARM提出了CMSIS标准,避免了各种基于ARM内核的CPU在软件定义时的混乱,最终目的还是减少嵌入式软件总是耗费精力在平台迁移带来的修改。图中的
Project目录栏里面的Doc目录很好理解,就是每个例程的readme.txt文件,User目录里面就是例程里面的源文件了,而Project目录栏里面的STM32F4xx_StdPeriph_Driver目录则是标准固件库里提供的STM32F4xx_DSP_StdPeriph_Lib_V1.8.0\Libraries\STM32F4xx_StdPeriph_Driver我们以流水灯为示例做一个简单的测试,此开发板的3个led灯是由GPIO的PIN0/PIN7/PIN14来控制的,因此使用Template里面的默认GPIO工程,main.c里main函数添加如下代码:
/* GPIOB Peripheral clock enable */ RCC_AHB1PeriphClockCmd(RCC_AHB1Periph_GPIOB, ENABLE); /* Configure PIN0/7/14 (led) */ GPIO_InitStructure.GPIO_Pin = GPIO_Pin_0 | GPIO_Pin_7 | GPIO_Pin_14; GPIO_InitStructure.GPIO_Speed = GPIO_Low_Speed; GPIO_InitStructure.GPIO_Mode = GPIO_Mode_OUT; GPIO_InitStructure.GPIO_OType = GPIO_OType_PP; GPIO_InitStructure.GPIO_PuPd = GPIO_PuPd_NOPULL; GPIO_Init(GPIOB, &GPIO_InitStructure); GPIO_WriteBit(GPIOB, GPIO_Pin_0 | GPIO_Pin_7 | GPIO_Pin_14, Bit_RESET); /* Infinite loop */ while (1) { Delay(50); GPIO_WriteBit(GPIOB, GPIO_Pin_0 | GPIO_Pin_7 | GPIO_Pin_14, Bit_SET); Delay(50); GPIO_WriteBit(GPIOB, GPIO_Pin_0 | GPIO_Pin_7 | GPIO_Pin_14, Bit_RESET); }然后按照
readme.txt文档里面的操作步骤,Rebuild all target files -> Start/Stop Debug Session -> Run 的过程,就可以看到3个不同颜色的led灯不停的闪烁了。需要注意在MDK的Options for Target里面Debug配置页配置调试器为ST-Link Debugger至此,使用标准固件库的基本方法就比较清晰了,如果要学习stm32的某个模块,可以用这样的方式学习标准固件库里提供的Example了,这种方式非常贴近底层,对深入学习非常有帮助。
CubeMx
CubeMx软件是针对ST系列的MCU提供的图形化配置软件,其目的在于让开发工程师最大可能的减少在MCU底层软件的配置修改上,将精力集中于自己的业务上,从ST官方提供的资料看来,这也是其主推的一种方式。如果使用ST系列的MCU,这确实是一种比较好的使用方式,如果在一家芯片公司,使用的是ARM核的自家MCU,这种方式就无法使用了。
下载安装STM32CubeMx v4.19.0,还是以上面的标准固件库点亮3个led灯为示例,这次使用CubeMx软件生成MDK工程。
STM32CubeMx可参考官方使用说明文档,需要首先安装Java 1.7版本及以上,然后安装STM32CubeMx,安装完成后就可以打开使用了。首先安装相应的固件包,软件界面
Help->Install New Libraries,进入到下面的界面,选择STM32CubeF4 Releases,在这栏里面选择最新的版本安装,此固件包对应开发板STM32F4xx系列,后面通过STM32CubeMx定制工程软件时就会用到此固件包。
安装完成后,在STM32CubeMx主界面,点击
New Project新建工程,看到下图所示,选择自己的开发板:
选好开发板后,就可以看到图形配置页面了:
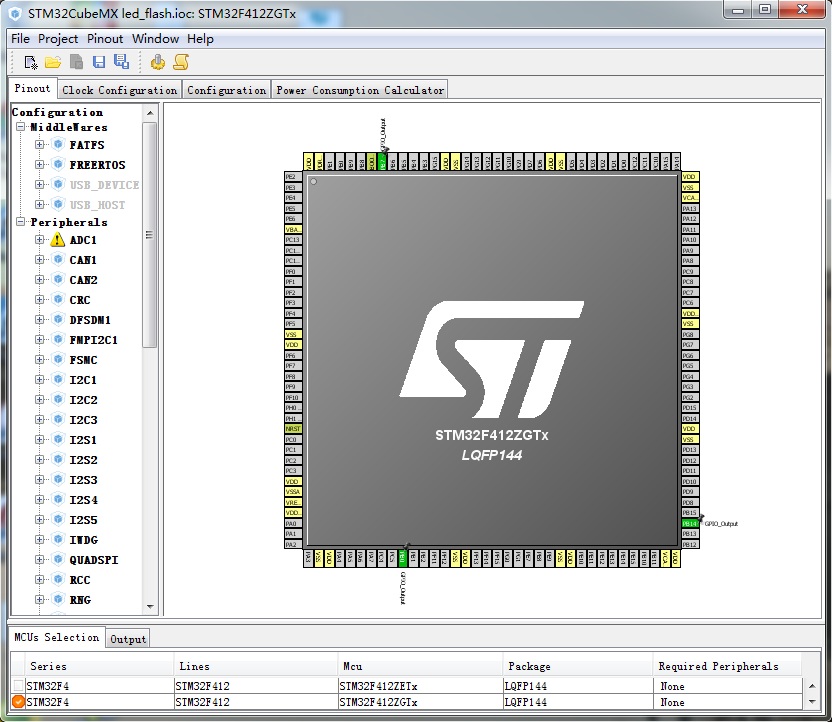
由于看原理图知道控制LED的3个GPIO管脚是PB0/PB7/PB14,因此可以直接在
Pinout页面的芯片的图片的这3个管脚上直接选择成GPIO_Output,如下图所示: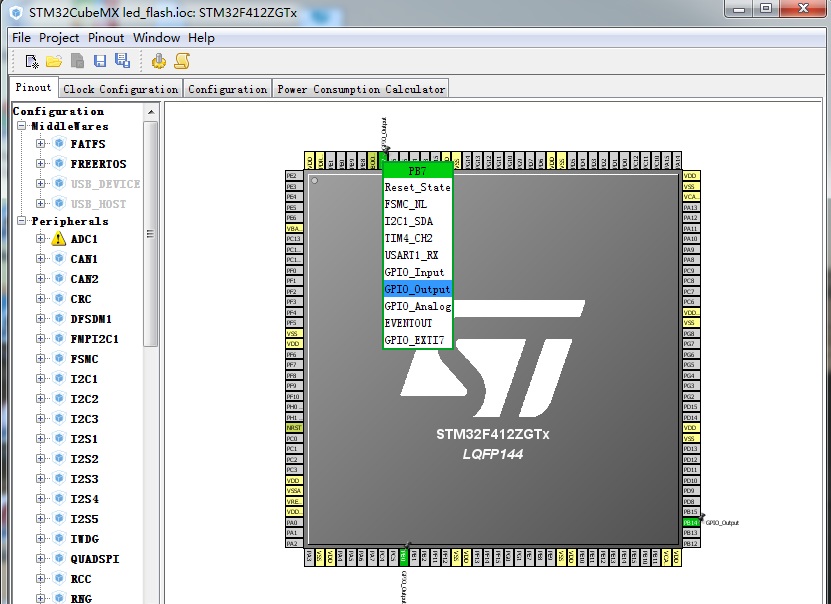
依次
Clock ConfigurationConfigurationPower Consumption Calculator暂时维持原配置不变,点击Generate source code based on user settings按钮,生成ARM MDK V5的工程: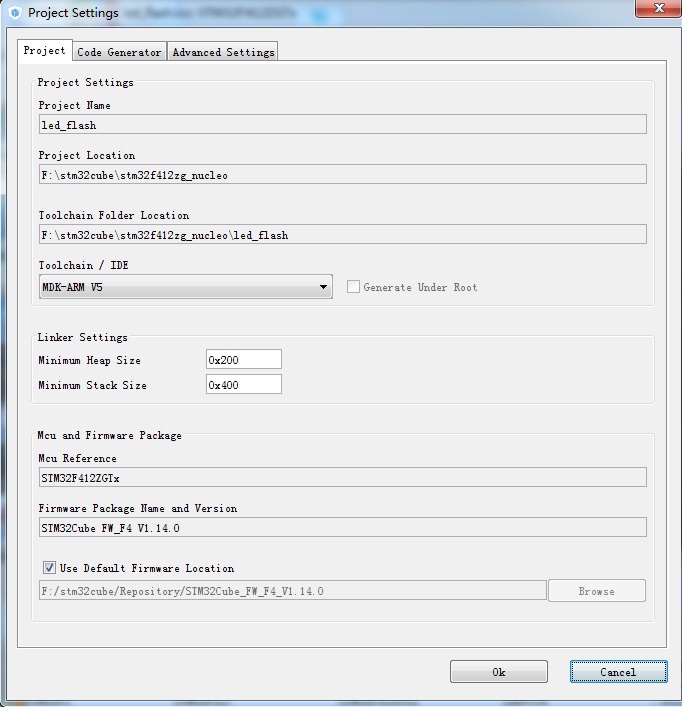
打开生成的工程,如下图:
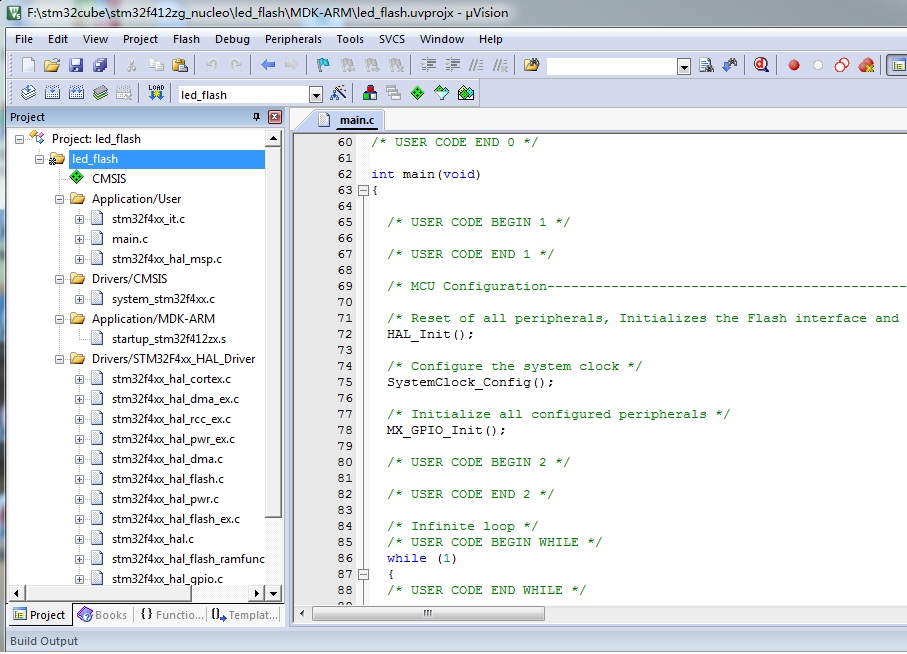
左侧工程栏与上面标准固件包工程非常相似,只是有些替换成了HAL层的文件名,HAL层是ST抽象出来的一层软件,确保在STM32各个产品之间实现最大限度的可移植性;main.c中的main函数可以看到初始化函数都写好了,而且注释可以看出添加用户代码的地方,在while(1)循环里添加循环点亮LED的代码:
/* Infinite loop */ /* USER CODE BEGIN WHILE */ while (1) { /* USER CODE END WHILE */ /* USER CODE BEGIN 3 */ HAL_GPIO_WritePin(GPIOB, GPIO_PIN_0|GPIO_PIN_14|GPIO_PIN_7, GPIO_PIN_SET); HAL_Delay(100); HAL_GPIO_WritePin(GPIOB, GPIO_PIN_0|GPIO_PIN_14|GPIO_PIN_7, GPIO_PIN_RESET); HAL_Delay(100); } /* USER CODE END 3 */与前面标准固件库示例类似,通过ARM MDK 5编译软件并下载到开发板,就可以看到3个LED等不停的闪烁。
RTOS
前面全部是直接在STM32上的firmware开发,现在复杂一些的应用全部是是要基于RTOS开发,而STM32CubeMx则选择FreeRTOS,并将FreeRTOS与USB/TCP/IP/图形等视为中间件,通过STM32CubeMx的图形化配置,可以选择支持哪个中间件,勾选后生成的工程中就自动包含了。
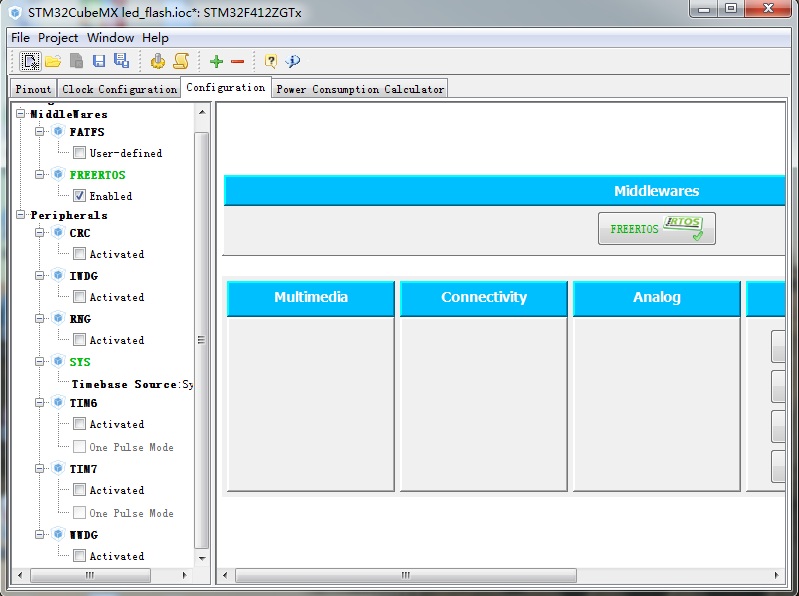
然后再点击生成MDK工程,生成工程时有个warning,提示rtos的Timebase Source不要使用systick,在
Pinout页面的SYS项配置里将Timebase Source选择为任意其他的TIM,这样warning就不存在了。主要原因是systick被用作了他用,因此产生了冲突。打开生成的工程,可以看到源码目录增加了一个Middlewares/FreeRTOS,全部是移植好的FreeRTOS源码,通过main.c里的main函数可以看到,多了FreeRTOS的初始化代码,而且这些RTOS源码是符合ARM的CMSIS-RTOS标准的,便于其他中间件和应用的移植。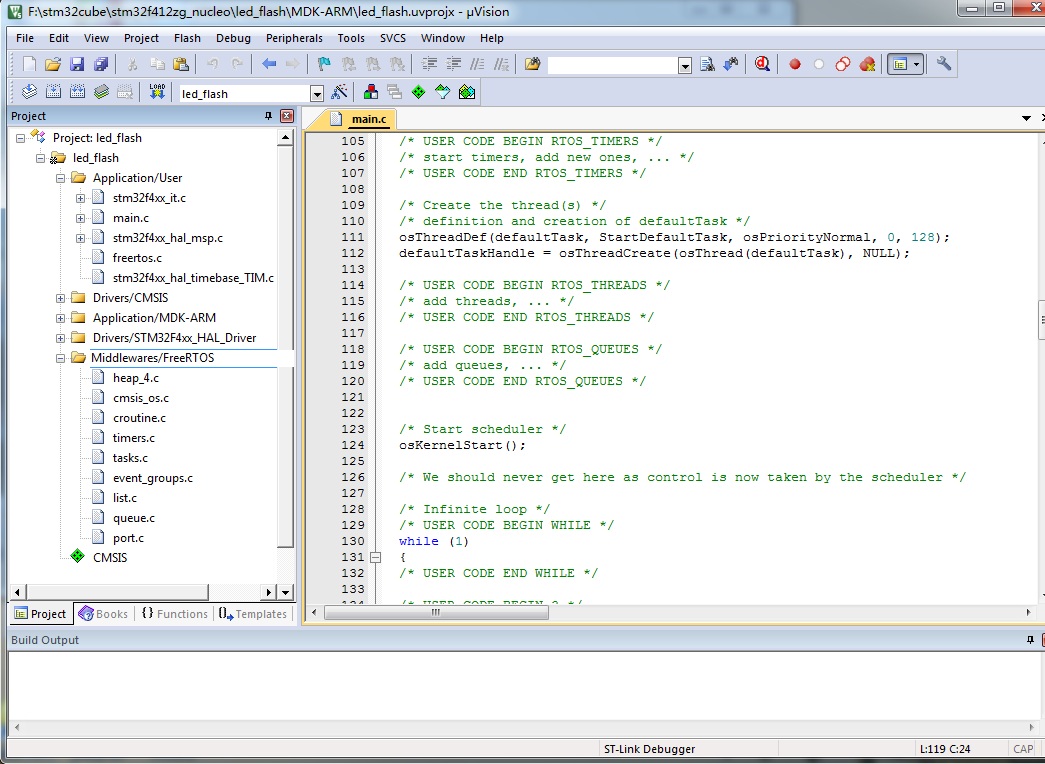
接下来还是以点亮LED为例,这次增加RTOS API的使用。创建2个task和1个MessageQueue,一个task接收消息,根据消息的value改变控制LED亮或者灭,另一个task周期性的发送消息改变LED状态。
在main.c里添加相应的代码,先把STM32CubeMx自动生成的代码里的创建defaultTask的示例代码去掉:
/* USER CODE BEGIN PV */ /* Private variables ---------------------------------------------------------*/ osThreadId ledFlashRxTaskHandle; osThreadId ledFlashTxTaskHandle; osMessageQId ledFlashMsgQ; /* USER CODE END PV */ ... int main(void) { ... /* Create the thread(s) */ /* definition and creation of defaultTask */ //osThreadDef(defaultTask, StartDefaultTask, osPriorityNormal, 0, 128); //defaultTaskHandle = osThreadCreate(osThread(defaultTask), NULL); /* USER CODE BEGIN RTOS_THREADS */ /* add threads, ... */ osThreadDef(ledFlashRxTask, StartLedFlashRxTask, osPriorityNormal, 0, 128); ledFlashRxTaskHandle = osThreadCreate(osThread(ledFlashRxTask), NULL); osThreadDef(ledFlashTxTask, StartLedFlashTxTask, osPriorityNormal, 0, 128); ledFlashTxTaskHandle = osThreadCreate(osThread(ledFlashTxTask), NULL); /* USER CODE END RTOS_THREADS */ /* USER CODE BEGIN RTOS_QUEUES */ /* add queues, ... */ osMessageQDef(ledFlashMsgQ, 100, uint32_t); ledFlashMsgQ = osMessageCreate(osMessageQ(ledFlashMsgQ), NULL); /* USER CODE END RTOS_QUEUES */ ... while(1); } ... /* StartLedFlashRxTask function */ void StartLedFlashRxTask(void const * argument) { osEvent evt; for(;;) { evt = osMessageGet(ledFlashMsgQ, osWaitForever); if (evt.status == osEventMessage) { if (evt.value.v == 0) HAL_GPIO_WritePin(GPIOB, GPIO_PIN_0|GPIO_PIN_14|GPIO_PIN_7, GPIO_PIN_RESET); else HAL_GPIO_WritePin(GPIOB, GPIO_PIN_0|GPIO_PIN_14|GPIO_PIN_7, GPIO_PIN_SET); } } } /* StartLedFlashTxTask function */ void StartLedFlashTxTask(void const * argument) { for(;;) { osMessagePut(ledFlashMsgQ, 0, osWaitForever); osDelay(500); osMessagePut(ledFlashMsgQ, 1, osWaitForever); osDelay(500); } }如果使用自家定制的ARM内核MCU,就需要考虑移植RTOS到自家平台上了,再做一下将FreeRTOS移植到开发板。首先到FreeRTOS官网上下载最新的FreeRTOS源码,参阅一下quick start。
FreeRTOS的目录结构也非常的简单:
Demo/ //FreeRTOS移植到各种平台的Demo License/ Source/ |-include/ //头文件 |-portable/ //移植需要的文件 |-Keil //分不同的编译器目录,MDK关注这个目录. port.c |-... |-MemMang //heap文件,一般选择heap_4.c |-croutine.c //这些*.c文件就是FreeRTOS的内核文件 |-event_groups.c |-list.c |-queue.c |-task.c |-timers.c |-readme.txtFreeRTOS的移植非常简洁,提供了各大主流平台相关的移植文件,而且区分主流的工具,因此移植到STM32F4xx上几乎不需要修改太多,只是选取相应的文件添加到工程里编译通过,就可以用起来了。
使用前面标准固件库里的工程,添加一个目录Middlewares/FreeRTOS,将FreeRTOS源码里的Source目录里的文件添加到Middlewares/FreeRTOS/里面,如下图所示:
Source/ |-include/ //全部copy过去 |-portable/ |-MemMang/ //全部copy,heap_4.c用的最多 |-heap_4.c |-... |-RVDS/ARM_CM4F/ //全部copy,ARM MDK工程与其相同 |-port.c |-portmacro.h |-croutine.c //所有的内核文件全部copy |-event_groups.c |-list.c |-queue.c |-task.c |-timers.c还需要借用STM32CubeMx生成的带FreeRTOS中间件工程里面的一个头文件FreeRTOSConfig.h,将其copy到工程里。
需要修改的内容,FreeRTOSConfig.h里面需要确认打开几个宏:
#define vPortSVCHandler SVC_Handler #define xPortPendSVHandler PendSV_Handler #define xPortSysTickHandler SysTick_Handlerstm32f4xx_it.c里面需要注释掉上面宏定义的3个中断处理函数,采用FreeRTOS提供的相应的3个函数,FreeRTOS相关的3个函数在port.c里面,属于平台相关。
//void SVC_Handler(void) //void PendSV_Handler(void) //void SysTick_Handler(void)移植工作就完成了,如果是自家平台,需要找一个类似的移植平台修改,从上面的过程可以看出,重点关注FreeRTOS/Source/Portable/[compiler]/[architecture]相关的平台相关的移植文件,以及FreeRTOSConfig.h这个FreeRTOS配置相关的文件。其他就如标准固件库里示例里讲到了启动文件startup_stm32xx.s,中断处理文件stm32xx_it.c,时钟相关文件system_stm32xx.c等,都是平台相关的。
再仿照上面STM32CubeMx生成的带FreeRTOS中间件工程,创建2个任务和1个队列,实现点亮LED的应用代码,main.c里面添加代码如下:
xQueueHandle MsgQueue; void vledFlashTxTaskFunc(void *pvParameters) { uint32_t zeroMsg = 0; uint32_t oneMsg = 1; for(;;) { vTaskDelay(500); if (MsgQueue != 0) xQueueSend(MsgQueue, (void *)&oneMsg, portMAX_DELAY); vTaskDelay(500); if (MsgQueue != 0) xQueueSend(MsgQueue, (void *)&zeroMsg, portMAX_DELAY); } } void vledFlashRxTaskFunc(void *pvParameters) { uint32_t recvNum = 0; for (;;) { if(xQueueReceive(MsgQueue, (void *)&recvNum, portMAX_DELAY) == pdPASS) { if (1 == recvNum) GPIO_WriteBit(GPIOB, GPIO_Pin_0 | GPIO_Pin_7 | GPIO_Pin_14, Bit_SET); else GPIO_WriteBit(GPIOB, GPIO_Pin_0 | GPIO_Pin_7 | GPIO_Pin_14, Bit_RESET); } } } void ledFlashGpioInit(void) { GPIO_InitTypeDef GPIO_InitStructure; /* GPIOB Peripheral clock enable */ RCC_AHB1PeriphClockCmd(RCC_AHB1Periph_GPIOB, ENABLE); /* Configure PIN0/7/14 (led) */ GPIO_InitStructure.GPIO_Pin = GPIO_Pin_0 | GPIO_Pin_7 | GPIO_Pin_14; GPIO_InitStructure.GPIO_Speed = GPIO_Low_Speed; GPIO_InitStructure.GPIO_Mode = GPIO_Mode_OUT; GPIO_InitStructure.GPIO_OType = GPIO_OType_PP; GPIO_InitStructure.GPIO_PuPd = GPIO_PuPd_NOPULL; GPIO_Init(GPIOB, &GPIO_InitStructure); GPIO_WriteBit(GPIOB, GPIO_Pin_0 | GPIO_Pin_7 | GPIO_Pin_14, Bit_RESET); } int main(void) { ledFlashGpioInit(); MsgQueue = xQueueCreate(10, sizeof(uint32_t)); xTaskCreate(vledFlashRxTaskFunc, "RxTask", configMINIMAL_STACK_SIZE, 0, 1, 0); xTaskCreate(vledFlashTxTaskFunc, "TxTask", configMINIMAL_STACK_SIZE, 0, 1, 0); vTaskStartScheduler(); while(1); }注意如何在ARM MDK里面添加
.c文件和添加相应的.h文件的Include Path,否则在*.c文件里添加#include “*.h”文件时就会报错找不到此头文件。小结
嵌入式MCU厂商非常了解用户的痛点,不需要用户再付出过多的精力在平台相关的改动上,而是专注在自己的业务上。ST让开发者可以忽略掉ST系列MCU的差异,而且还提供了丰富的中间件支持,让业务的开发更加便捷。对CMSIS标准的支持,让开发者的应用也更加容易移植。FreeRTOS精简的内核加上各主流平台移植的支持,以及丰富的开源中间件支持,无愧为开源嵌入式实时操作系统的一哥。